
Schematizzazione del reindirizzamento dei canali di input e di output attraverso gli operatori di redirezione
Le istruzioni di uno script Bash sono costituite da assegnazioni di valori a variabili (es.: “a=3”, “nome='Marco Liverani'”, ecc.) o da comandi costituiti da specifiche parole chiave riservate, seguite eventualmente da parametri costanti o da variabili; in questo caso le variabili sono precedute dal simbolo “$”, come ad esempio in “echo $nome”, per distinguere il nome della variabile da una stringa costante, come in “echo nome”.
I comandi che possono essere utilizzati in uno script Bash sono distinti in due insiemi: i comandi interni, resi disponibili dall'interprete, ed i comandi esterni, resi disponibili dal sistema operativo in cui viene eseguito l'interprete e lo script (ad esempio il sistema operativo UNIX). Ci soffermeremo nel seguito prevalentemente sui primi, i comandi interni, ma è bene sottolineare che gli script Bash esprimono la loro massima flessibilità e potenza anche perché consentono una integrazione estremamente semplice con i comandi del sistema operativo e con altri script realizzati nello stesso linguaggio o con altri linguaggi di scripting.
Ad esempio il comando “date” è un programma presente nel set di base delle utility di tutti i sistemi operativi UNIX; al contrario, il comando “echo” è un comando interno della Bash. Sia il programma “date” (comando esterno) che l'istruzione “echo” (comando interno) possono essere utilizzati nello stesso modo come istruzioni di uno shell script, senza che sia necessario invocare il programma esterno con forme sintattiche particolari.
1 #!/bin/bash
2 echo -n "Oggi e' il "
3 date +%d/%m/%Y
Il comando interno “type” accetta come argomento una o più stringhe di caratteri e fornisce in output l'indicazione del tipo di comando o parola chiave a cui corrisponde ciascuna stringa. Riportiamo di seguito un esempio per l'uso del comando “type”:
$ type echo ls cat [ { xyz
echo is a shell builtin
ls is aliased to `ls -F'
cat is /bin/cat
[ is a shell builtin
{ is a shell keyword
-bash: type: xyz: not found
Un'altra importante distinzione che possiamo compiere analizzando alcuni aspetti generali relativi alla programmazione della shell è la seguente: in termini piuttosto semplificati possiamo dire che i comandi della shell si distinguono in comandi semplici e comandi composti. Un comando semplice è costituito da una singola istruzione riportata su una riga dello script. Un comando composto è costituito da una lista di comandi semplici, eseguiti in modo “unitario” dalla shell. I comandi che formano la lista sono separati l'uno dall'altro da uno dei seguenti operatori: “;”, “&”, “&&”, “||”.
Il carattere “;” consente di separare un comando dal successivo nell'elenco che compone la lista, senza introdurre un comportamento specifico nell'esecuzione dei comandi da parte della shell.
1 a=3; b=4; echo "I valori sono $a e $b"
Il carattere “&” consente invece di eseguire in background il comando che lo precede (per un maggiore approfondimento tra la modalità di esecuzione in background e in foreground di un programma e la descrizione dei comandi che consentono di controllare lo stato di esecuzione di un processo, si vedano ad esempio [2] e [5]). In pratica viene lanciato un altro processo, come processo “figlio” di quello che sta eseguendo lo script, eseguito indipendentemente dal processo “padre”.
L'esecuzione di ciascun comando restituisce all'interprete Bash un codice di ritorno (return code) numerico; tale codice viene interpretato come un valore logico di vero (return code uguale a zero) e falso (return code diverso da zero). Uno script shell può restituire un codice di ritorno mediante il comando interno “exit”, che interrompe l'esecuzione dello script e accetta come argomento il codice di ritorno da restituire.
| A | B | A and B | A or B |
|---|---|---|---|
| vero | vero | vero | vero |
| vero | falso | falso | vero |
| falso | vero | falso | vero |
| falso | falso | falso | falso |
Gli operatori “&&” e “||” rappresentano i connettori logici and e or, rispettivamente, e possono essere utilizzati per sfruttare il codice di ritorno restituito dai comandi. Tenendo conto del significato dei connettori logici and e or, richiamato in Tabella, il comportamento dell'interprete, che esegue i comandi di una lista interpretandoli da sinistra verso destra, a fronte di un'istruzione di questo genere:
comando1 && comando2
è il seguente: il primo comando viene eseguito e, se restituisce il valore vero, allora viene eseguito anche il secondo comando (il resto della lista dei comandi); in caso contrario l'esecuzione della lista dei comandi viene interrotta. In altri termini comando2 viene eseguito se e solo se comando1 restituisce zero come return code. Infatti l'interprete esegue la lista per desumere il codice di ritorno complessivo dell'intero comando composto: se il primo comando della lista restituisce il valore falso ed è connesso al resto della lista mediante l'operatore logico and, è inutile proseguire la valutazione della lista, dal momento che il valore dell'intero comando composto non potrà che essere falso.
L'operatore “||” si comporta nel modo opposto; a fronte di un'istruzione composta di questo tipo:
comando1 || comando2
se comando1 restituisce il valore vero, l'elaborazione del comando composto viene interrotta perché è già possibile stabilire il valore restituito dall'intero comando, dal momento che il connettore logico che unisce comando1 al resto della lista è l'operatore or. In caso contrario, se comando1 restituisce il valore falso, allora l'interprete esegue anche i comandi successivi e ne valuta il return code per poter stabilire il valore dell'intero comando composto. Ossia, comando2 viene eseguito se e solo se il return code di comando1 è diverso da zero.
Sfruttando le considerazioni appena riportate possiamo costruire un comando composto che implementa una sorta di struttura di controllo condizionale, del tipo “se ... allora ... altrimenti ...”:
(comando1 && comando2) || comando3
Se comando1 restituisce il valore vero allora viene eseguito anche comando2, altrimenti, se comando1 restituisce il valore falso, viene eseguito comando3.
La lista di istruzioni che forma un comando composto può essere anche delimitata da parentesi tonde, graffe o quadre: ogni tipo di delimitatore della lista di istruzioni ha un significato diverso e ben preciso, descritto nella sezione seguente.
In termini più analitici si può dire che la shell Bash è in grado di elaborare i seguenti tipi di istruzioni fornite in modalità interattiva dall'utente sulla linea di comando o inserite nelle righe di uno script:
Nelle pagine seguenti di questo capitolo introduciamo i costrutti più elementari per la definizione di comandi composti, mediante la redirezione dell'input e dell'output, la costruzione di pipeline e la valutazione di condizioni. Nei capitoli successivi saranno introdotte le istruzioni con cui possono essere implementate le strutture di controllo algoritmiche condizionali e iterative e la definizione di funzioni.
Se la lista di istruzioni con cui viene formato un comando composto è delimitata da parentesi graffe, le istruzioni che compongono la lista vengono eseguite in sequenza, dalla prima all'ultima, all'interno della stessa shell in cui viene eseguito lo script. Le istruzioni sono separate fra loro da un punto e virgola. Anche l'ultima istruzione della lista deve essere seguita da un punto e virgola e tra le parentesi graffe e la prima e l'ultima istruzione deve essere presente uno spazio: le parentesi graffe sono infatti delle parole riservate del linguaggio Bash e non dei simboli di carattere sintattico, dunque devono essere separate da uno spazio dalle parole chiave “circostanti”. Consideriamo ad esempio il seguente script, piuttosto elementare.
1 #!/bin/bash
2 a=1; b=2
3 echo "Prima del comando composto: A = $a, B = $b"
4 { b=3; echo "Durante il comando composto: A = $a, B = $b"; }
5 echo "Dopo il comando composto: A = $a, B = $b"
Con le istruzioni a riga 2 vengono definiti i valori delle variabili a e b, che vengono poi visualizzati sul terminale dell'utente con l'istruzione alla riga 3. La sequenza di istruzioni che costituiscono il comando composto a riga 4 viene eseguita come un singolo comando, nell'ambito della stessa shell in cui viene eseguito lo script; infatti la variabile a definita fuori dal comando composto è ancora visibile nel comando stesso ed inoltre l'istruzione a riga 5 permette di verificare che il valore della variabile b è stato modificato.
L'effetto dell'esecuzione dello script precedente è il seguente; lo scope delle due variabili a e b è esteso a tutte le istruzioni dello script:
$ ./script.sh
Prima del comando composto: A = 1, B = 2
Durante il comando composto: A = 1, B = 3
Dopo il comando composto: A = 1, B = 3
Potrebbe sembrare non molto utile raggruppare più istruzioni in un unico comando composto attraverso l'uso delle parentesi graffe, tuttavia, come vedremo più avanti, l'uso delle parentesi graffe diventa assai utile in diverse circostanze, come ad esempio quando si intende applicare all'intero comando composto un operatore di redirezione dell'input/output.
Se le istruzioni che costituiscono il comando composto sono delimitate da parentesi tonde, allora il comando composto viene eseguito in una sotto-shell della shell in cui gira lo script; questo significa che il comando composto eredita tutte le variabili definite nello script, ma lo scope delle assegnazioni e delle definizioni effettuate nell'ambito del comando composto è limitato al comando stesso. Il comando composto viene eseguito in una sotto-shell, ma nello stesso processo della shell con cui viene eseguito lo script.
Lo script seguente, analogo all'esempio precedente, dovrebbe aiutare a chiarire il funzionamento di questo tipo di comandi composti, evidenziando la differenza con i comandi composti delimitati da parentesi graffe:
1 #!/bin/bash
2 a=1; b=2
3 echo "Prima del comando composto: A = $a, B = $b"
4 (b=3; echo "Durante il comando composto: A = $a, B = $b")
5 echo "Dopo il comando composto: A = $a, B = $b"
L'output prodotto eseguendo lo script è riportato di seguito; l'aspetto significativo di questo esempio è costituito dal fatto che il comando composto (riga 4) può utilizzare le variabili definite in precedenza nello script (variabile a) e può modificare il valore delle variabili (variabile b), tuttavia le modifiche effettuate dal comando composto non sono visibili al termine del comando stesso. Nell'esempio che segue, infatti, il valore di b viene modificato dal comando composto, ma al termine del comando la variabile assume nuovamente il valore impostato in precedenza (riga 2 dello script).
Prima del comando composto: A = 1, B = 2
Durante il comando composto: A = 1, B = 3
Dopo il comando composto: A = 1, B = 2
A differenza delle parentesi graffe, le parentesi tonde che delimitano il comando composto non sono delle parole riservate del linguaggio, per cui non è necessario separarle dalle altre istruzioni con degli spazi; per lo stesso motivo, l'ultima istruzione della lista può anche non essere seguita da un punto e virgola.
Nell'ambito degli script Bash è possibile effettuare operazioni aritmetiche con una sintassi simile a quella del linguaggio C. Un aspetto molto significativo di cui è necessario tenere conto è che le operazioni aritmetiche valutate dall'interprete Bash operano solo nell'ambito dei numeri interi; dunque determinate espressioni, che ci si potrebbe aspettare diano luogo ad un risultato non intero, producono un risultato per cui la parte decimale viene troncata. Ad esempio dall'espressione “3/2” si ottiene il risultato 1 e non 1.5 come ci si sarebbe potuti aspettare.
Le espressioni aritmetiche vengono valutate dall'interprete Bash solo se sono rappresentate come comandi composti delimitati da una coppia di doppie parentesi tonde: “((espressione))”. Ad esempio per assegnare ad una variabile il risultato di un'espressione aritmetica, che può anche coinvolgere altre variabili, possiamo usare le seguenti istruzioni:
1 ((a=($b+37)/$c))
2 a=$(( ($b+37)/$c ))
Nelle espressioni aritmetiche delimitate dalle doppie parentesi tonde è possibile omettere il simbolo “$” davanti alle variabili a cui si vuole fare riferimento: in ogni caso un termine letterale sarà considerato come il nome di una variabile. Per cui l'espressione precedente può anche essere riscritta come segue:
1 a=$(( (b+37)/c ))
Il seguente script fornisce un esempio abbastanza chiaro del modo in cui devono essere codificate le istruzioni che contengano espressioni aritmetiche al loro interno:
1 #!/bin/bash
2 a=5; b=2
3 c=$a/$b
4 echo "a=$a, b=$b, c=$c"
5 ((c=a/b))
6 echo "a=$a, b=$b, c=$c"
Lo script produce l'output riportato di seguito. In pratica l'espressione aritmetica riportata a riga 3 viene ignorata in quanto tale e considerata semplicemente come una concatenazione di stringhe: alla variabile c viene assegnato il valore di a, seguito da un carattere “/” e dal valore di b. Per assegnare alla variabile c il risultato dell'espressione aritmetica “a/b” bisogna utilizzare l'istruzione riportata a riga 5, dove viene fatto correttamente uso delle doppie parentesi tonde per delimitare il comando contenente una o più espressioni da valutare.
$ ./script.sh
a=5, b=2, c=5/2
a=5, b=2, c=2
È importante osservare che l'istruzione “((...))” restituisce un codice uguale a zero se il valore dell'espressione aritmetica all'interno delle doppie parentesi è diverso da zero, mentre avrà un return code diverso a zero se il valore dell'espressione è uguale a zero.
Come di consueto, le espressioni aritmetiche possono utilizzare le parentesi tonde per modificare l'ordine con cui vengono valutati i singoli termini. Gli operatori aritmetici sono gli stessi che ritroviamo anche in linguaggio C e in molti altri linguaggi di programmazione. Per semplicità in Tabella sono riportati i principali.
| Operatore | Descrizione |
|---|---|
| ++, -- | Incremento e decremento di un'unità |
| +, -, *, /, % | Somma, sottrazione, moltiplicazione, divisione intera, resto della divisione intera |
| ** | Elevamento a potenza |
| <<, >> | Shift a sinistra e a destra di un bit |
Come in linguaggio C sono disponibili degli operatori di assegnazione in forma compatta: “++”, “--”, “+=”, “-=”, “*=”, “/=”, “%=”. Questi operatori consentono di assegnare alla variabile posta sulla sinistra dell'operatore il risultato di un'operazione aritmetica elementare tra il valore della variabile stessa ed il valore dell'espressione posta alla destra dell'operatore.
Ad esempio l'espressione “((a+=1))” è equivalente alle espressioni “((a=a+1))”, “((a++))” e “((++a))”. Allo stesso modo l'espressione “((a/=2))” è equivalente all'espressione “((a=a/2))”, che però è meno sintetica ed efficiente.
Osserviamo che l'espressione “(($a++))” è sbagliata e produce un errore: l'interprete Bash, infatti, nel valutare l'istruzione per prima cosa sostituisce il riferimento alla variabile a con il suo valore e quindi prova ad eseguire l'operatore “++” sul valore numerico; quest'ultima operazione (es.: “5++”) è impropria, perché l'operatore “++” si applica ad una variabile e non ad un numero, visto che oltre ad incrementare di un'unità il valore, l'operatore assegna il nuovo valore alla variabile riportata a sinistra dell'operatore stesso.
Nell'ambiente delimitato dalle doppie parentesi tonte è possibile anche effettuare confronti fra espressioni aritmetiche utilizzando operatori molto simili a quelli utilizzati anche in altri linguaggi di programmazione, come ad esempio il C; per comodità sono riportati in Tabella.
| Operatore | Descrizione |
|---|---|
| >, >= | Maggiore, Maggiore o uguale |
| <, <= | Minore, Minore o uguale |
| ==, != | Uguale, Diverso |
Nelle espressioni possono essere utilizzate le congiunzioni logiche “&&” (and) e “||” (or) per costruire condizioni di confronto più complesse. Il seguente comando composto dovrebbe aiutare a chiarire alcuni dei concetti fin qui espressi:
1 (( $a!=0 )) && ( (( $b/$a>=1 )) && echo "Ok" || echo "Ko") || \
2 echo "Divisione per zero"
Il comando è composto da una sola espressione molto lunga, spezzata su due righe per ragioni di spazio: il backslash alla fine della prima riga indica che l'istruzione non è completa e prosegue alla riga successiva. Di fatto questo comando composto implementa delle strutture di controllo condizionali “nidificate”: se il valore della variabile a è diverso da zero, allora esegue la divisione b/a e confronta il risultato con il valore 1; se il risultato è maggiore o uguale ad 1 allora visualizza il messaggio “Ok”, altrimenti visualizza “Ko”; se invece il valore di a è zero, allora non esegue la divisione e visualizza il messaggio “Divisione per zero”.
È spesso utile effettuare dei confronti fra stringhe o sullo stato di un file presente sul filesystem della macchina. Per far questo la Bash mette a disposizione un insieme di operatori di confronto che per essere utilizzati devono essere riportati in un comando composto delimitato dalle doppie parentesi quadre: “[[...]]”.
| Operatore | Descrizione |
|---|---|
| -a, -e | Vero se il file esiste |
| -s | Vero se il file esiste ed ha dimensione maggiore di zero byte |
| -d, -f, -h | Vero se il file esiste ed è una directory, o un file regolare, o un link |
| -r, -w, -x | Vero se lo script ha i privilegi di lettura, o di scrittura, o di esecuzione sul file |
| -nt, -ot | Vero se il primo file è più recente del secondo (newer than) o se il secondo è più recente del primo (older than) |
Il primo tipo di operatori di confronto per la costruzione di espressioni condizionali consente di verificare lo stato dei file. In Tabella sono riportati i principali operatori di questo genere. Il seguente esempio aiuterà a comprendere meglio la sintassi degli operatori:
1 [[ -e /etc/shadow ]] && echo 'Shadow password attivo' || \
2 echo 'Shadow password non attivo'
Questo comando composto visualizza il messaggio “Shadow password attivo” se esiste il file /etc/shadow, altrimenti visualizza il messaggio “Shadow password non attivo”.
Il seguente comando composto visualizza il contenuto del file il cui nome è memorizzato nella variabile $file se l'utente ha il permesso di leggerlo, altrimenti visualizza un messaggio di errore:
1 [[ -r $file ]] && cat $file || echo 'Privilegi insufficienti'
Infine, il seguente comando composto cancella il file $file3 se è più vecchio di $file1 e di $file2:
1 [[ $file1 -nt $file3 && $file2 -nt $file3 ]] && rm $file3
Nell'ambito di un comando composto per la valutazione di espressioni condizionali possono essere confrontate fra loro anche stringhe ed espressioni il cui valore sia un numero intero. Per il confronto tra stringhe la Bash mette a disposizione gli operatori riportati in Tabella. È importante inserire uno spazio tra gli operandi e l'operatore di confronto.
| Operatore | Descrizione |
|---|---|
| ==, != | Vero se le due stringhe sono uguali (identiche anche nel case dei caratteri) o diverse (anche solo nel case dei caratteri: "Abc" != "abc") |
| <, > | Vero se la prima stringa precede (o segue) in ordine lessicografico la seconda |
| -n | Vero se la stringa ha una lunghezza maggiore di zero |
Nella valutazione dell'ordine reciproco di due stringhe vale il cosiddetto “ordine lessicografico”, realizzato confrontando l'ordine reciproco della prima coppia di caratteri differenti con la medesima posizione nell'ambito della stringa; l'ordine reciproco dei caratteri alfanumerici è quello stabilito dalla tabella dei codici ASCII (per visualizzare la tabella dei codici ASCII in ambiente UNIX è sufficiente digitare il comando “man ascii”). Ad esempio la stringa “abc100” precede, in ordine lessicografico, la stringa “abc20”; analogamente la stringa “100” precede la stringa “11”. Se le due stringhe hanno lunghezze differenti e la stringa s1 è un “prefisso” della stringa s2, allora s1<s2. Ad esempio “10”<“100”; analogamente “10”<“100”<“9”.
Il seguente esempio aiuterà a comprendere l'uso e la sintassi degli operatori di confronto fra stringhe:
1 [[ "$a" == "$b" ]] && echo "Sono uguali" || echo "Sono diversi"
Se le due espressioni da confrontare sono dei numeri interi, allora è possibile effettuare un confronto numerico anche utilizzando le doppie parentesi quadre come delimitatori dell'espressione; questo è utile nel caso in cui si debba definire una condizione mista, composta da confronti fra numeri, file e stringhe: in questo caso non è possibile utilizzare una condizione delimitata da doppie parentesi tonde (valutazione di espressioni aritmetiche), ma è necessario l'uso delle doppie parentesi quadre.
Per il confronto fra espressioni numeriche devono essere utilizzati degli operatori appositi, distinti da quelli utilizzati in questo contesto per il confronto fra stringhe: l'interprete deve infatti distinguere tra un tipo di confronto e l'altro, dal momento che per le stringhe vale l'ordine lessicografico, diverso dall'ordinamento naturale dei numeri interi. Ad esempio 100>99, mentre invece la stringa “100” precede, nell'ordine lessicografico, la stringa “99”, per cui risulta“100”<“99”. Gli operatori di confronto fra espressioni numeriche sono riportati in Tabella.
| Operatore | Descrizione |
|---|---|
| -eq, -ne | Vero se le due stringhe hanno lo stesso valore intero o due valori interi differenti |
| -lt, -le | Vero se la prima stringa ha un valore minore o minore o uguale al valore della seconda |
| -gt, -ge | Vero se la prima stringa ha un valore maggiore o maggiore o uguale al valore della seconda |
Di seguito presentiamo un esempio con un'espressione condizionale mista, in cui viene effettuato il confronto tra stringhe e tra numeri interi:
1 [[ "$a" < "$b" && $a -lt $b ]] && \
2 echo "Sono in ordine come stringhe e come numeri" || \
3 echo "Non sono in ordine in almeno uno dei due casi"
Nel comando precedente, spezzato per comodità su tre righe di testo, a riga 1 viene valutata un'espressione condizionale “mista” (un confronto fra stringhe di caratteri e un confronto fra numeri): il valore delle variabili a e b viene confrontato utilizzando un operatore di confronto fra stringhe, per stabilire se a precede in ordine lessicografico b. Se questa condizione dà esito positivo (il confronto restituisce il valore vero) viene valutata anche la seconda condizione del comando composto: le stesse variabili a e b vengono confrontate verificando se il valore intero della prima è minore del valore intero della seconda. In caso di esito positivo anche di questo secondo confronto viene visualizzato il primo messaggio, in caso contrario (se il primo o, in subordine, il secondo confronto ha restituito il valore falso) viene visualizzato il secondo messaggio.
Ad esempio se $a='123' e $b='456' il comando visualizzerà il messaggio “Sono in ordine come stringhe e come numeri”; se invece $a='abc1' e $b='abc2' il comando visualizzerà il messaggio “Non sono in ordine in almeno uno dei due casi”, perché i due valori sono in ordine lessicografico corretto, ma valutandone il contenuto come numeri interi, entrambe le variabili hanno un valore pari a zero e dunque non sono una minore dell'altra.
Una delle caratteristiche che rende maggiormente flessibile l'uso dei comandi della shell Bash e dei comandi esterni resi disponibili dal sistema operativo, è la possibilità di effettuare la cosiddetta redirezione dell'input/output. In pratica si tratta della possibilità di redirigere l'output prodotto da un comando e che generalmente sarebbe visualizzato sullo schermo del terminale dell'utente, verso un file o verso il canale di standard input di un altro programma; analogamente è possibile fare con l'input, facendo sì che l'input generalmente ricevuto da un programma attraverso la tastiera del terminale dell'utente, venga invece acquisito da un file.
In generale ogni programma eseguito in modalità batch o interattiva ha a disposizione tre canali di input/output standard: il canale di standard input, con cui tipicamente riceve l'input dalla tastiera del terminale su cui opera l'utente, il canale di standard output, su cui invia i messaggi da visualizzare sul terminale dell'utente, ed il canale standard error, su cui vengono inviati i messaggi di errore prodotti dal programma stesso. Ai tre canali di input/output sono associati gli identificativi 0, 1 e 2, rispettivamente.
Schematizzazione del reindirizzamento dei canali di input e di output attraverso gli operatori di redirezione
Mediante gli operatori di redirezione dell'I/O è possibile modificare il comportamento standard nell'uso di questi tre canali da parte del programma, reindirizzandoli su dei file o concatenando fra di loro più programmi, in modo che l'uno riceva in input ciò che un altro programma ha prodotto come output.
Per reindirizzare il canale di input in modo che il comando acquisisca l'input da un file, si deve utilizzare l'operatore “<” (o anche “0<”) per separare il comando dal nome del file:
comando < file
Ad esempio, il comando “sort” legge in input una sequenza di righe di testo e le presenta in output ordinate in ordine crescente. Le righe di testo vengono lette generalmente da uno o più file il cui nome è specificato sulla riga di comando, come argomento del comando “sort”. Tuttavia di default il comando legge le righe di testo dal canale di input standard, per cui è possibile eseguire il comando “sort” e poi digitare una di seguito all'altra le righe da ordinare; al termine dell'inserimento della sequenza è sufficiente battere la sequenza di tasti Control-D per concludere l'input e permettere al comando di visualizzare in output la sequenza ordinata in ordine lessicografico crescente. La sequenza di caratteri Control-D rappresenta il carattere di fine file (EOF: end of file) con cui il sistema operativo indica ad un programma che il file che sta leggendo è terminato e che non ci sono altri dati da leggere in input. Una volta ricevuto in input il carattere di fine file, il comando “sort” invia in output la sequenza ordinata, come nel seguente esempio:
$ sort
topo
cane
gatto
Control-D
cane
gatto
topo
Se la sequenza di parole da ordinare è contenuta in un file (il file “animali” nell'esempio che segue), allora è possibile redirigere il canale standard input in modo tale che l'input sia acquisito dal file:
$ sort < animali
cane
gatto
topo
In modo analogo è possibile operare una redirezione dell'output inviandolo, anziché sullo schermo del terminale dell'utente, su un file. Supponiamo di voler ordinare una sequenza di nomi forniti in input dall'utente (che concluderà l'immissione dei dati digitando la sequenza di tasti Control-D ) e di volerla memorizzare in un file. L'esempio che segue chiarisce l'uso dell'operatore “>” che consente di redirigere l'output di un comando; il comando viene riportato alla sinistra dell'operatore, mentre sulla destra viene indicato il nome di un file:
comando > file
$ sort > animali
topo
cane
gatto
Control-D
$ cat animali
cane
gatto
topo
Naturalmente i comandi di redirezione dell'input e dell'output possono essere utilizzati simultaneamente, utilizzando una sintassi di questo tipo:
comando < file input > file output
Ad esempio, supponiamo che il file “animali” contenga un elenco di nomi di animali non ordinati. Con il comando che segue possiamo produrre il file “animali_ordinato” contenente gli stessi nomi, ma in ordine alfabetico crescente:
$ sort < animali > animali_ordinato
Il comando dell'esempio precedente non produce alcun messaggio sullo schermo del terminale, né richiede da parte dell'utente che sia digitata alcuna informazione in input, perché sia il canale di input standard che quello di output standard sono stati rediretti su dei file. L'esito del comando è comunque quello desiderato, anche se apparentemente non è accaduto nulla, come si può provare utilizzando il comando “cat” per visualizzare il contenuto del file “animali_ordinato”:
$ cat animali_ordinato
cane
gatto
topo
La shell, a fronte di un comando utilizzato con l'operatore di redirezione dell'output “>”, crea il file specificato a destra dell'operatore e indirizza tutto ciò che il comando invia sul canale standard output su tale file; al termine dell'esecuzione del comando il file viene chiuso. Se il file già esiste, questo viene cancellato automaticamente viene ricreato un file con lo stesso nome.
Naturalmente per poter utilizzare l'operatore di redirezione dell'output l'utente che esegue lo script o il comando deve possedere i permessi di scrittura per la creazione del file sul filesystem.
Per redirigere l'output su un file già esistente, senza cancellarlo, ma accodando l'output del comando al termine del contenuto già presente nel file, invece dell'operatore “>”, si deve utilizzare l'operatore “>>”. Ad esempio, il seguente comando, aggiunge le righe del file “primo” al file “secondo”:
$ cat primo >> secondo
Come abbiamo accennato nelle pagine precedenti, il sistema operativo mette a disposizione dei programmi e dei comandi eseguiti dagli utenti, due diversi canali di output: lo standard output (identificato dal “descrittore” 1) e lo standard error (identificato dal “descrittore” 2). Il primo, come abbiamo visto, è il canale di output standard, che coincide con lo schermo del terminale dell'utente e può essere rediretto su un file (o su un altro device) mediante gli operatori “>” e “>>”. Il secondo è dedicato alla visualizzazione di messaggi di errore o che comunque non rientrano nel normale output del programma. Redirigendo su un file lo standard output i messaggi inviati sul canale standard error saranno comunque visualizzati sul terminale dell'utente.
A titolo di esempio consideriamo il seguente programma scritto in linguaggio C, che visualizza due messaggi sui due diversi canali di output.
1 #include <stdlib.h>
2 #include <stdio.h>
3 int main(void) {
4 fprintf(stdout, "Messaggio inviato su standard output.\n");
5 fprintf(stderr, "Messaggio inviato su standard error.\n");
6 return(0);
7 }
Per poter eseguire il programma precedente è necessario compilarlo, producendo un programma eseguibile in linguaggio macchina. Per far questo bisogna eseguire il compilatore C, che generalmente, sui sistemi UNIX che ne sono dotati, corrisponde al comando “cc” o “gcc”. Supponiamo quindi che il sorgente del programma in linguaggio C sia memorizzato nel file “programma.c”; con il seguente comando si esegue il compilatore C e si ottiene in output il file eseguibile “programma”.
$ cc programma.c -o programma
Lanciando in esecuzione il programma eseguibile si ottiene l'output seguente:
$ ./programma
Messaggio inviato su standard output.
Messaggio inviato su standard error.
Utilizzando l'operatore di redirezione dell'output verso un file si ottiene esclusivamente la redirezione dell'output inviato al canale standard output, mentre ciò che è stato inviato su standard error sarà comunque visualizzato sul terminale dell'utente:
$ ./programma > file
Messaggio inviato su standard error.
$ cat file
Messaggio inviato su standard output.
Per redirigere su un file ciò che è stato inviato sul canale standard error è necessario utilizzare l'operatore “2>”, con la stessa sintassi con cui si è utilizzato l'operatore “>”; è possibile anche redirigere i due canali di output (standard output e standard error) su due file differenti con lo stesso comando, utilizzando entrambi gli operatori di redirezione dell'output “>” e “2>”:
$ ./programma 2> file
Messaggio inviato su standard output.
$ cat file
Messaggio inviato su standard error.
$ ./programma > file.output 2> file.error
$ cat file.output
Messaggio inviato su standard output.
$ cat file.error
Messaggio inviato su standard error.
È possibile anche redirigere il canale standard error sullo standard output o viceversa: nel primo caso si userà l'operatore di redirezione “2>&1”, mentre nel secondo caso si userà l'operatore “1>&2”. Infine, con l'operatore di redirezione “&>” si redirigono entrambi i canali standard output e standard error su un file:
$ ./programma &> file
$ cat file
Messaggio inviato su standard error.
Messaggio inviato su standard output.
Chiudiamo questa sezione ricordando che nelle pagine precedenti avevamo introdotto la sintassi “{ lista di comandi; }”, dicendo che poteva essere utile per redirigere l'output di più programmi eseguiti in successione, su uno stesso file. Per far questo è possibile utilizzare un'espressione di questo tipo:
{ comando1; comando2; ...; comandon; } > file
Di seguito riportiamo un esempio elementare di redirezione su uno stesso file dell'output prodotto da più comandi lanciati in sequenza:
$ { date +%d/%m/%Y; finger; } > utenti_collegati
$ cat utenti_collegati
26/06/2011
Login Name TTY Idle Login Time Office Phone
marco Marco Liverani *con 4:31 Dom 18:49
marco Marco Liverani s00 Dom 19:24
Lo stesso risultato poteva essere ottenuto senza utilizzare le parentesi graffe per costruire il comando composto e usando l'operatore di redirezione “>>” (append) per redirigere l'output del secondo comando sul file, senza distruggere l'output prodotto dal primo comando. Ad esempio:
$ date +%d/%m/%Y > utenti_collegati; finger >> utenti_collegati
$ cat utenti_collegati
26/06/2011
Login Name TTY Idle Login Time Office Phone
marco Marco Liverani *con 4:31 Dom 18:49
marco Marco Liverani s00 Dom 19:24
Oltre alla redirezione dell'input e dell'output, una delle caratteristiche più interessanti ed utili della shell Bash è costituita dalla possibilità di concatenare tra loro due o più programmi inviando sul canale di standard input di uno ciò che viene prodotto sul canale di standard output di un altro. Questa operazione di concatenazione di programmi attraverso i loro canali di input e di output è nota in gergo con il nome di pipe (“tubo”, in italiano). L'operatore di pipe su Bash è rappresentato dal carattere “|”: l'output del comando alla sinistra dell'operatore viene passato in input al comando posto sulla destra dell'operatore.
Ad esempio, con la seguente istruzione si invia l'output del comando “ls -1” al comando “wc -l”:
$ ls -1 | wc -l
15
Nell'esempio viene eseguito il comando “ls” con l'opzione “-1” per ottenere un elenco dei nomi dei file presenti nella directory corrente, costituito da un solo nome per ogni riga; l'output di questo comando (una sequenza di righe contenente ciascuna il nome di un file), viene passato in input al comando “wc” che, con l'opzione “-l”, esegue il conteggio delle righe in input e lo stampa in output. In questo modo, con la concatenazione mediante il pipe dei due comandi, viene visualizzato il numero di file presenti nella directory corrente.
Sulla stessa riga di comando possono essere utilizzati più operatori di pipe per costruire delle vere e proprie catene di operazioni che, prima di produrre l'output finale, passano i dati attraverso una sequenza di “filtri”.
$ du -sk * | sort -rn | head -5
10348 mail
10200 src
10044 tex
7344 documenti
5876 tmp
Quest'ultimo esempio è più complesso del precedente, perché utilizza una doppia concatenazione con pipe. Il comando “du” (disk usage) con l'opzione “-sk” produce l'elenco dei nomi dei file presenti nella directory corrente preceduti dalla dimensione di ciascuno in KByte. L'output di questo comando viene passato in input al comando “sort” che, con le opzioni “-rn”, dispone in ordine decrescente (“-r”, reverse) le righe ricevute in input considerando l'ordinamento numerico (“-n”, numeric) e non quello lessicografico basato sulla sequenza dei caratteri nella tabella dei codici ASCII con cui si sarebbe ottenuto, ad esempio, che “10”<“2”; il comando “sort” quindi si occupa di “filtrare” l'output del comando “du”, rielaborarlo cambiando l'ordine delle righe, per passarlo poi in input al comando “head”. Quest'ultimo comando, con l'opzione “-5”, visualizza solo le prime cinque righe ricevute in input.
Complessivamente quindi l'istruzione composta del precedente esempio consente di visualizzare i nomi dei cinque file di dimensione maggiore tra quelli presenti nella directory corrente. Possiamo schematizzare quest'ultimo esempio con il disegno riportato in Figura.
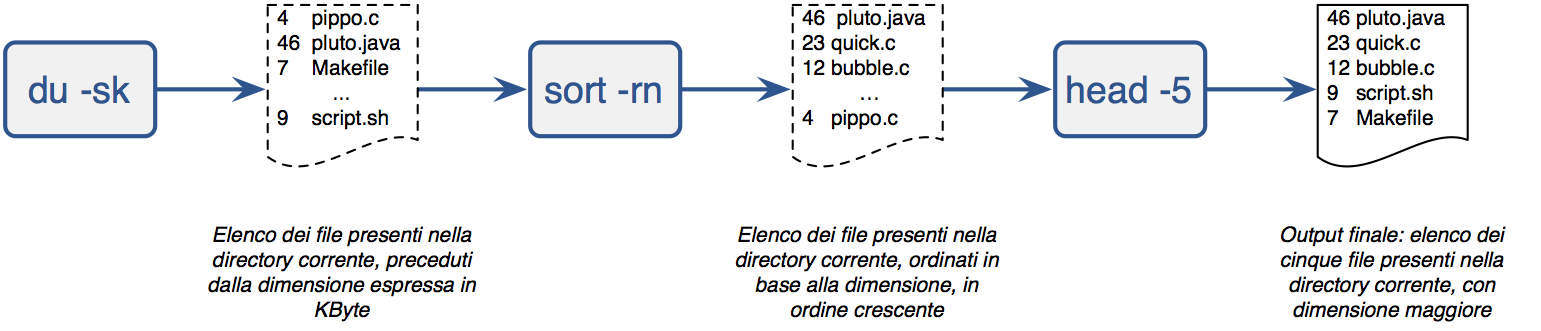
Schematizzazione della concatenazione di comandi con l'operatore pipe; solo l'ultimo degli output prodotto dai comandi della pipeline viene visualizzato sul terminale dell'utente, mentre gli altri output intermedi (nella figura rappresentati in un box tratteggiato) sono passati da un comando all'altro, senza essere mostrati all'utente
Anche con l'operatore pipe è possibile utilizzare le parentesi graffe per aggregare l'output prodotto da più comandi prima di inviarlo in input al comando successivo; anche in questo caso la sintassi è la seguente:
{ comando1 ; comando2 ; ... ; comandon ; } | comandon+1
Ad esempio, il seguente comando aggrega l'output prodotto dai due comandi “du” eseguiti con parametri diversi: il primo calcola la dimensione di tutti i file con estensione “.c” presenti nella sottodirectory “src”, il secondo calcola la dimensione dei file con estensione “.tex” presenti nella sottodirectory “tex”; l'output aggregato, come se fosse prodotto da un solo comando, viene inviato in input (attraverso l'operatore pipe) al comando “sort”; l'output prodotto da quest'ultimo viene infine inviato al programma “head” che, con l'opzione “-6”, restituirà sullo schermo del terminale solo le prime sei righe dell'output prodotto da “sort”:
$ { du -sk src/*.c ; du -sk tex/*.tex ; } | sort -rn | head -6
68 tex/grafi_clique.tex
20 src/grafica.c
16 tex/IN1.tex
8 tex/soluzione.tex
8 tex/kruskal.tex
8 src/cgilib.c
Comandi interni, esterni e composti
Variabili, varibili d'ambiente e variabili speciali
Sintesi dei comandi principali
