Schema del processo di invio/ricezione di un messaggio di e-mail
In questo capitolo diamo un rapido sguardo ai comandi principali della shell del sistema operativo Unix. Questi comandi ci consentono di eseguire programmi, di spostarci nelle directory del filesystem e di gestire facilmente i file e le funzioni di base del sistema.
Al di là delle funzionalità semplificate offerte da alcuni desktop manager in ambiente grafico, il modo migliore per interagire con un sistema Unix è attraverso una shell. È un programma che interpreta ed esegue i comandi immessi dall'utente sulla base di un linguaggio che descriveremo per grandi linee nelle pagine seguenti. La shell in genere viene eseguita in modalità interattiva, ossia in una modalità secondo cui la shell attende che l'utente immetta un comando, poi lo interpreta e lo esegue e ritorna nello stato di attesa per il comando successivo; tuttavia la shell può essere utilizzata anche come interprete per l'esecuzione di un intero programma scritto nel linguaggio della stessa shell: un programma per la shell sarà quindi una sequenza di comandi e di istruzioni in grado di controllare e di modificare l'ordine con cui tali comandi devono essere eseguiti. Un programma per la shell viene chiamato in gergo uno script (o shell script).
La shell è il programma che di solito viene eseguito automaticamente dal sistema quando un utente effettua il login; questa specifica istanza della shell viene quindi chiamata shell di login.
Volendo fare un parallelo con il sistema operativo Windows, possiamo dire che la shell svolge più o meno la stessa funzione del programma command.com o di cmd.exe, ma è molto più potente e versatile. Gli shell script sono quindi l'analogo dei file batch (i file "*.bat") in ambiente Windows.
Esistono diverse shell sotto Unix: tra queste citiamo la Bourne Shell (scritta da Stephen Bourne), che può essere richiamata con il comando sh, la bash, o Bourne Again Shell, un'evoluzione di sh, la Korn Shell ksh, la C Shell csh, molto amata dai programmatori in quanto ha una sintassi simile a quella del linguaggio C, la tcsh, evoluzione della C Shell, ed altre ancora. In effetti le differenze tra queste shell sono numerose, ma risultano evidenti soprattutto scrivendo degli script, perché per il resto sono abbastanza simili fra loro.
È importante osservare che in ambiente Unix le lettere maiuscole e minuscole sono completamente diverse: sotto Windows scrivendo DIR e dir ci si riferisce allo stesso comando, come pure è possibile riferirsi ad un certo file chiamandolo pippo.txt o PIPPO.TXT indifferentemente. Sotto Unix non vale la stessa cosa: i nomi dei comandi sono case sensitive e devono essere digitati rispettando le lettere maiuscole e minuscole e lo stesso vale per i nomi dei file e delle directory. Inoltre non esistono limitazioni sui nomi dei file: questi possono essere anche molto lunghi e non è necessaria l'"estensione"; di fatto il simbolo "." è un carattere come ogni altro nel nome del file (ma ha una funzione particolare se utilizzato come primo carattere del nome di un file, come vedremo tra breve) ed anche il carattere di spaziatura può far parte del nome del file, anche se personalmente sconsiglio di utilizzarlo perché ci obbliga ad usare delle accortezze ulteriori per riferirci successivamente a quel file. Ad esempio potremmo chiamare il file che contiene il testo di questo capitolo "guida unix.capitolo-2".
Abbiamo già detto che per accedere alla macchina si deve effettuare una procedura di "riconoscimento" detta login. Il sistema ci chiede innanzi tutto di inserire il nostro username e poi la password segreta. Per capire meglio vediamo un esempio:
woodstock login: marco
Password:
Last login: Fri Apr 21 10:27:08 on ttyS2
$ _
La password non viene visualizzata a video quando la inseriamo, per impedire a chi ci sta guardando di scoprirla e poter quindi accedere al sistema a nome nostro; al contrario lo username è la componente pubblica del nostro account di utenti del sistema e serve agli altri per poter comunicare con noi, come vedremo nelle pagine seguenti. Il messaggio "Last login..." ci comunica la data e l'ora dell'ultima volta che siamo entrati nel sistema ed il nome del terminale da cui ci siamo collegati, in questo caso il terminale ttyS2. Questo è un messaggio utile, perché ci permette di controllare se per caso ci sono state intrusioni fraudolente a nostro nome sul sistema, da parte di qualcuno che è riuscito a scoprire la nostra password.
Il simbolo "$" che viene visualizzato davanti al cursore è il prompt, ossia l'indicazione che la shell è pronta ad accettare un nostro comando immesso da tastiera; quello riportato in queste pagine è solo un esempio: il prompt potrebbe variare da sistema a sistema o essere configurato diversamente dall'utente (vedremo più avanti come è possibile modificare il prompt). Tipicamente l'utente root ha un prompt diverso da quello degli altri utenti, proprio per evidenziare all'operatore che sta utilizzando comandi che saranno eseguiti con i privilegi di root e non con quelli del suo account personale: commettere un errore, anche solo per una semplice distrazione, potrebbe avere effetti disastrosi sull'integrità del sistema. Negli esempi di questa guida indicheremo con "#" il prompt di root.
Per cambiare la password si deve digitare il comando passwd: il sistema chiederà di inserire prima la vecchia password e poi, se questa è corretta, chiederà per due volte (per sicurezza) di inserire la nuova password che l'utente intende impostare per proteggere il proprio account. Gli username e le password cifrate, insieme ad altre informazioni di base sugli utenti accreditati sul sistema, sono memorizzate nel file /etc/passwd, che tutti gli utenti possono visualizzare. Su alcuni sistemi, per maggiore sicurezza, le password sono memorizzate invece nel file /etc/shadow (sempre in forma cifrata) e tale file è leggibile solo dall'utente root.
Quando abbiamo finito di lavorare, prima di andarcene, dobbiamo scollegarci, effettuare cioè la procedura di logout che serve proprio per comunicare al sistema che abbiamo terminato di lavorare e che quindi può chiudere la sessione rimettendosi in attesa del prossimo utente. Per scollegarci possiamo usare il comando exit, o il comando logout se stiamo lasciando la shell di login; in alcune shell anche la sequenza di tasti Ctrl-d (che corrisponde al carattere di "fine-file") produce lo stesso effetto. Effettuato il logout il sistema presenterà nuovamente il messaggio di login in attesa che qualcun'altro si colleghi dallo stesso terminale.
Di norma nei CED e nei centri di calcolo i terminali vengono lasciati sempre accesi, ma, salvo esplicita controindicazione, è possibile anche spegnerli dopo che si è effettuato il logout. È fondamentale invece non spegnere mai la macchina che ospita il sistema: solo root può effettuare la procedura di shutdown al termine della quale sarà possibile spegnere il computer. Non si deve mai spegnere un sistema Unix senza prima aver completato la procedura di shutdown, pena la perdita irreparabile dei dati del filesystem. Di seguito riportiamo un frammento della sequenza di shutdown di una macchina in ambiente Linux: durante questa fase il sistema operativo invia il segnale di terminazione a tutti i processi attivi, in modo che questi possano concludere l'esecuzione chiudendo correttamente eventuali file aperti.
# shutdown -h now
Broadcast message from root (pts/1) Tue Aug 30 17:03:16 2005...
The system is going down for system halt NOW !!
...
System halted.
Appena entrati nel sistema ci troviamo all'interno della nostra home directory. Per verificare il nome della directory possiamo usare il comando pwd (print working directory).
$ pwd
/home/marco
$ _
Il simbolo "/" (slash), oltre ad indicare la root directory del filesystem, è utilizzato come separatore tra le directory che fanno parte di uno stesso path; sui sistemi Windows la stessa funzione è svolta dal carattere "\" (backslash).
Di sicuro la prima cosa che ci viene in mente è quella di visualizzare il contenuto della nostra directory. Per far questo si deve usare il comando ls (list), equivalente al comando dir del prompt dei comandi di Windows. Ad esempio potremmo ottenere il seguente output:
$ ls
lettera mail pippo.c progetto tesi
libro pippo pippo.zip src
$ _
Vengono visualizzati nove nomi, ma non è chiaro se siano nomi di file di dati, di sottodirectory o di programmi eseguibili. Abbiamo accennato precedentemente alle numerose opzioni che generalmente consentono di modificare opportunamente l'esecuzione di un certo comando o programma; in generale una riga di comando è costituita dal comando stesso seguito da una sequenza di opzioni indicate mediante caratteri (o sequenze di caratteri) preceduti dal simbolo "-", e da parametri che vengono passati al comando. Le opzioni consentono di modificare in parte il modo con cui il comando viene eseguito. Ad esempio potremmo provare la seguente variante del comando ls:
$ ls -F /home/marco
lettera mail/ pippo.c progetto@ tesi/
libro/ pippo* pippo.zip src/
$ _
Il comando è "ls", la sequenza "-F" rappresenta un'opzione del comando, mentre "/home/marco" è il parametro passato al comando stesso. L'opzione "-F" del comando ls fa sì che accanto ad alcuni nomi di file venga visualizzato un simbolo che non fa parte del nome, ma che serve ad indicare di che tipo di file si tratta: lo slash "/" indica che è una directory, l'asterisco "*" indica che si tratta di un file eseguibile, mentre la chiocciola "@" sta ad indicare che quel file (o directory) non è fisicamente presente nella nostra directory, ma è un link, un rimando, un collegamento, ad un file (o ad una directory) che si trova da un'altra parte nel filesystem.
Si ottiene un'altra versione del comando ls aggiungendo l'opzione "-l" (long); visto che è possibile specificare più opzioni su uno stesso comando, vediamo quale potrebbe essere l'output del comando "ls -lF" (che equivale anche ad "ls -l -F", visto che in molti casi le opzioni dei comandi possono essere "raggruppate"):
$ ls -lF
-rw-r--r-- 1 marco users 937 Apr 23 12:43 lettera
drwxr-xr-x 2 marco users 1024 Apr 10 16:04 libro/
drwx------ 2 marco users 1024 Feb 01 09:32 mail/
-rwxr-x--- 1 marco users 37513 Mar 10 11:55 pippo*
-rw-r--r-- 1 marco users 18722 Mar 10 11:30 pippo.c
-rw-r--r-- 1 marco users 23946 Mar 10 12:03 pippo.zip
lrwxrwxr-- 1 marco users 8 Apr 04 18:16 progetto -> /usr/proj
drwxrwx--- 2 marco users 1024 Mar 10 08:47 src/
drwxr--r-- 2 marco users 1024 Feb 12 1995 tesi/
$ _
Illustriamo brevemente il significato delle numerose informazioni presentate dal comando "ls -l". Il primo carattere di ogni riga può essere "d" per indicare che si tratta di una directory, "l" per indicare un link o "-" per indicare che si tratta di un normale file. I successivi nove caratteri rappresentano in forma sintetica i permessi di accesso assegnati ai file; devono essere letti raggruppandoli a tre a tre. I primi tre caratteri indicano i diritti del proprietario di tale file sul file stesso; i successivi tre caratteri indicano i diritti degli altri utenti facenti parte del gruppo proprietario del file, mentre gli ultimi tre caratteri rappresentano i diritti di tutti gli altri utenti del sistema. Una "x" sta ad indicare il diritto di esecuzione di tale file (mentre è chiaro cosa significa eseguire un programma, è opportuno chiarire che "eseguire" una directory significa poterci entrare dentro). Il carattere "r" sta ad indicare il diritto di leggere tale file (read), mentre "w" indica il diritto di poterci scrivere sopra (write), modificandolo o cancellandolo.
Di seguito viene riportato lo username del proprietario del file (es.: marco) ed il nome del gruppo di appartenenza (es.: users). Viene poi visualizzata la dimensione del file, la data e l'ora in cui è stato creato (o modificato per l'ultima volta) ed infine il nome.
Nell'esempio il file pippo.zip può essere letto e modificato dal proprietario (marco), mentre può essere soltanto letto dagli altri utenti del sistema; è stato creato il 10 Marzo dell'anno in corso alle 12:03. Il file progetto è un link alla directory /usr/proj e può essere utilizzato in lettura, scrittura ed esecuzione solo dal proprietario e dagli utenti del gruppo users, ma non dagli altri utenti del sistema che possono solo accedervi in lettura.
Delle numerosissime opzioni del comando ls ci limitiamo ad illustrarne solo un'altra, che ci permette di introdurre anche qualche interessante novità a proposito dei nomi dei file; cominciamo con il solito esempio, osservando l'output prodotto dal comando "ls -a":
$ ls -aF
./ .bashrc lettera pippo* progetto@
../ .exrc libro/ pippo.c src/
.Xdefaults .newsrc mail/ pippo.zip tesi/
$ _
Da dove spuntano questi strani file preceduti da un punto e perché fino ad ora non li avevamo visti? Per convenzione sotto Unix (ma anche in ambiente Windows) il nome "." (punto) sta ad indicare la directory corrente, mentre con ".." si indica la directory "padre" nell'albero del filesystem(1). Gli altri file preceduti dal punto sono dei normali file (o directory, ma non nel nostro caso) che però non vengono visualizzati dal comando ls proprio perché hanno un nome che comincia con il punto. In questo modo possiamo evitare di visualizzare alcuni file che devono essere presenti nella nostra directory (ad esempio i file di configurazione), ma che non utilizzeremo direttamente quasi mai e dei quali dimenticheremo presto la presenza. Visualizzarli ogni volta renderebbe l'output del comando ls eccessivamente ridondante e quindi tali file vengono, in un certo senso, "nascosti".
Per spostarsi attraverso le directory del filesystem si usa il comando cd (change directory). Ad esempio per "scendere" nella directory src si dovrà digitare il comando "cd src", mentre per risalire nella directory padre (la nostra home directory) dovremo digitare il comando "cd ..". A proposito della home directory è utile osservare che ci si può riferire ad essa mediante l'uso del simbolo "~" (tilde), mentre per riferirsi alla home directory dell'utente "marina" si potrà usare la stringa "~marina" (ad esempio si potrà digitare "cd ~marina" per spostarci nella sua directory: questo modo di impostare il comando è sicuramente più sintetico del canonico "cd /home/marina"). Visto che si presenta frequentemente la necessità di rientrare nella propria home directory, il comando cd dato senza nessun parametro assolve efficacemente tale scopo.
Abbiamo visto nella sezione precedente che ad ogni file sono associati degli attributi per regolare l'accesso da parte degli utenti del sistema. Per modificare gli attributi di un file si deve utilizzare il comando chmod, che ha la seguente sintassi: "chmod attributi file".
Il parametro attributi può avere varie forme, ma forse la più semplice di tutte è quella numerica, secondo la seguente regoletta. Si associa valore 100 al diritto di eseguire il file per il proprietario, 10 per gli utenti del gruppo e 1 per tutti gli altri; si associa 200 al diritto di accesso in scrittura al file per il proprietario, 20 per gli utenti del gruppo e 2 per tutti gli altri; infine si associa 400 al diritto di accesso in lettura al file per il proprietario, 40 per gli utenti del gruppo e 4 per gli altri. Sommando questi numeri si ottiene l'attributo da assegnare a quel file. Così, ad esempio, il parametro 700 equivale a stabilire che l'unico a poter leggere, scrivere ed eseguire il file è il proprietario (100+200+400=700), mentre con 644 si indica il fatto che il file può essere letto e modificato dal proprietario, ma può essere soltanto letto dagli altri utenti; in quest'ultimo caso, volendo associare tale attributo al file pippo.c daremo il comando
$ chmod 644 pippo.c
$ _
Per creare una directory si usa il comando mkdir (make directory); ad esempio con il comando
$ mkdir esempio
$ _
possiamo creare una nuova directory nella directory corrente.
Per rimuovere una directory vuota (che non contiene alcun file) si deve usare invece il comando rmdir (remove directory); ad esempio:
$ rmdir esempio
$ _
Il comando viene prontamente eseguito dal sistema senza chiederci ulteriore conferma. La directory non viene cancellata se contiene al suo interno dei file o delle sottodirectory (è necessario eliminare prima tali file e directory per poter poi cancellare la directory che li conteneva).
Per creare una copia di un file si deve usare il comando cp (copy); ad esempio volendo copiare il file pippo.c nella directory src dovremo dare il comando:
$ cp pippo.c src
$ _
Sintassi analoga ha anche il comando mv (move) che serve a spostare i file da una directory all'altra, ad esempio per spostare tutti i file il cui nome termina con ".c" dalla directory src alla directory tesi potremo dare il seguente comando:
$ mv src/*.c tesi
$ _
Possiamo utilizzare il comando mv anche per cambiare il nome ad un file, ad esempio se volessimo modificare il nome del file pippo.c e chiamarlo pluto.c, potremmo usare il comando:
$ mv pippo.c pluto.c
$ _
Infine per cancellare un file si usa il comando rm (remove); si deve porre particolare attenzione nell'uso di questo comando, perché se non si specifica l'opzione "-i" (interactive), il sistema eseguirà la cancellazione dei file senza chiedere ulteriori conferme. Ad esempio il seguente comando cancella ogni file contenuto nella directory tesi:
$ rm tesi/*
$ _
Usando l'opzione "-i" il sistema ci chiede conferma dell'operazione; alla domanda del sistema si deve rispondere con "y" (yes) oppure con "n" (no):
$ rm -i pippo.c
rm: remove `pippo.c'? y
$ _
Con l'opzione "-r" il comando rm può essere utilizzato anche per cancellare "ricorsivamente" una directory con tutti i file e le sottodirectory in essa contenuti; naturalmente i file e le directory su cui l'utente non ha permesso di accesso in scrittura non potranno essere rimossi:
$ rm -r src
$ _
Per sapere quanto spazio occupa una certa directory o ogni singolo file presente in una directory, si può usare il comando du (disk usage); ad esempio il comando "du -sk *" visualizza il numero di Kbyte occupati da ogni sigolo file presente nella directory corrente. Al contrario per sapere quanto spazio è ancora libero in ogni singola partizione del filesystem si può utilizzare il comando df (disk free); il seguente comando visualizza lo spazio libero ed occupato su ogni partizione in Kbyte:
$ df -k
Filesystem kbytes used avail capacity Mounted on
/dev/dsk/c0t0d0s0 245679 111360 109752 51% /
/dev/dsk/c0t0d0s6 3098743 1916210 1120559 64% /usr
/proc 0 0 0 0% /proc
/dev/dsk/c0t0d0s5 2055463 1289267 704533 65% /var
swap 1138744 64 1138680 1% /tmp
/dev/dsk/c0t0d0s7 32016550 5201840 26494545 17% /export
$ _
Per individuare la collocazione di un file o una directory nel filesystem si può utilizzare il comando find che consente di cercare uno o più file sulla base del nome o di un pattern che deve corrispondere a quello dei nomi dei file cercati. Il comando è piuttosto sofisticato e consente di effettuare numerose operazioni sui file trovati. Per visualizzare semplicemente il path dei file individuati si può usare la seguente sintassi: "find path -name pattern -print". I parametri path e pattern indicano rispettivamente il percorso della directory radice del sottoalbero del filesystem in cui si vuole eseguire la ricerca (indicheremo "/" se vogliamo compiere una ricerca su tutto il filesystem) e il pattern (descritto con un'espressione regolare) a cui deve corrispondere il nome dei file che stiamo cercando (ad esempio "pippo.c" se cerchiamo esattamente un file con quel nome, oppure "es*.c" se cerchiamo tutti i file il cui nome inizia con "es" e termina con ".c"). Ad esempio per cercare tutti i file il cui nome termina con ".txt" nella directory corrente (e nelle sue sottodirectory), possiamo usare il seguente comando:
$ find . -name "*.txt" -print
./src/dati.txt
./relazione/tmp/lettera.txt
$_
È molto utile poter visualizzare e stampare il contenuto di un file di testo. Ancora più utile è poterne creare di nuovi e modificarne il contenuto. Anche perché per la configurazione delle caratteristiche fondamentali di un sistema Unix o anche soltanto dell'ambiente di lavoro di un singolo utente, è necessario modificare il contenuto di alcuni file di configurazione, costituiti appunto da semplici file di testo che contengono alcune istruzioni in un formato ben noto e documentato (Unix è un sistema operativo aperto!). Dunque visualizzare, stampare e poi anche creare e modificare il contenuto di un file sono operazioni che qualunque utente di un sistema Unix deve saper compiere con una certa agilità. A questo scopo sono stati implementati diversi comandi: in questa sezione ne vedremo solo alcuni, quelli che riteniamo veramente indispensabili, rimandando al prossimo Capitolo 3 la descrizione degli editor principali.
Il primo comando, ed anche il più elementare, è cat, che serve per concatenare due o più file, ma che può essere usato anche per visualizzare il contenuto di un file di testo. Ad esempio il seguente comando visualizza sul terminale il contenuto del file pippo.c (un banale programmino in linguaggio C):
$ cat src/ciao.c
#include <stdlib.h>
#include <stdio.h>
int main(void) {
printf("Ciao!\n");
return(1);
}
$ _
Se il file è molto lungo e non può essere visualizzato all'interno di una schermata del terminale, l'output scorrerà sullo schermo fino all'ultima riga del file, senza che sia possibile leggerne il contenuto. Per ovviare a questo problema si usa il comando more, che, come cat, visualizza il contenuto del file sullo schermo, ma alla fine di ogni schermata rimane in attesa che l'utente batta un tasto prima di visualizzare la schermata successiva. Il comando less è una evoluzione di more ed offre qualche funzionalità in più per scorrere le righe del file; su alcuni sistemi more è un alias di less. I comandi interattivi more e less accettano diversi tasti per scorrere il contenuto del file visualizzato:
Il comando more può anche essere utilizzato per filtrare verso il terminale l'output proveniente da un altro comando, attraverso la possibilità di effettuare il piping dei comandi messa a disposizione dalla shell. Ad esempio se l'output del comando "ls -l" dovesse essere troppo lungo potremmo utilizzare il comando "ls -l | more" che prima di inviare l'output al terminale lo filtra attraverso more, visualizzandolo una schermata alla volta.
Per visualizzare in modo più confortevole il contenuto di un file, si può utilizzare il comando view (o anche "vi -R") che consente di scorrere il contenuto di un file di testo utilizzando i tipici tasti di spostamento del cursore; per terminare la visualizzazione del file con view è necessario digitare la sequenza ":q".
Visualizzare sullo schermo del terminale il contenuto di un file che non contenga del semplice testo composto da caratteri ASCII standard (ad esempio un file binario o un file che contenga informazioni codificate in un altro modo) potrebbe produrre l'invio al terminale di sequenze di caratteri in grado di compromettere la sessione di lavoro sul terminale stesso. È bene quindi assicurarsi della natura del contenuto di un file prima di visualizzarlo sullo schermo con cat o altri comandi analoghi. Per far questo si può utilizzare il comando file che visualizza in output il tipo di dati contenuti nel file il cui nome gli è stato passato come argomento; ad esempio:
$ file src/ciao.c
src/ciao.c: ASCII C program text
$ file /bin/ls
/bin/ls: ELF 32-bit MSB executable SPARC Version 1, dynamically
linked, stripped
$ _
Nel primo caso (il file ciao.c) si tratta di un file di testo ASCII il cui contenuto può essere visualizzato correttamente con cat, mentre nel secondo caso (il file /bin/ls che contiene l'eseguibile del comando ls) si tratta di un file binario che non può essere visualizzato con il comando cat o uno degli altri comandi visti poc'anzi.
I comandi head e tail consentono rispettivamente di visualizzare la parte iniziale e la parte finale di un file di testo ASCII. Di default entrambi visualizzano le prime o le ultime 10 righe del file, ma con l'opzione "-n" si può estendere o ridurre la selezione ad n righe. Inoltre il comando tail ammette anche l'opzione "-f" che consente di tenere aperto un certo file e di visualizzare le ultime righe man mano che queste vengono aggiunte al file stesso; è un comando utilissimo per tenere sotto controllo il contenuto di un file di log o di un file di dati prodotto da un programma in esecuzione; ad esempio per visualizzare in tempo reale il file di log principale del sistema si può usare il comando "tail -f /var/log/syslog" (per terminare il comando si deve battere Ctrl-c ).
Il comando wc (word count) consente di contare i caratteri, le parole o le righe contenute in un certo file; ad esempio per contare il numero di account utente presenti sul sistema si può usare il seguente comando:
$ wc -l /etc/passwd
398 /etc/passwd
$ _
L'uso della stampante è una tipica operazione "site dependent", che varia a seconda del tipo di stampante e dei cosiddetti filtri di stampa installati sul sistema.
La differenza sostanziale è tra file di testo (scritti con un normale editor, senza fare uso di particolari caratteri di controllo o di formattazione del testo) che contengono solo caratteri ASCII, e file PostScript (che di solito sono riconoscibili perché il nome termina con ".ps") che contengono una rappresentazione di livello "tipografico" di un documento o di una immagine grafica. Se la stampante è una stampante generica sarà più semplice stampare i primi, se è una stampante PostScript sarà invece assai semplice stampare il secondo tipo di file. In ogni caso, come per quasi ogni altra operazione sotto Unix, nulla è impossibile e quindi saremo anche in grado di stampare normali file di testo su stampanti Postscript e file Postscript su stampanti generiche.
Il comando fondamentale in questo caso è lpr. Come more anche questo può essere usato sia come comando che come filtro per l'output di un altro programma. Così ad esempio i due comandi "lpr pippo.c" e "cat pippo.c | lpr" sono assolutamente equivalenti e producono entrambi la stampa del file pippo.c. In questo caso abbiamo inviato alla coda di stampa un file di testo che potrà essere stampato correttamente se il sistema dispone di una stampante generica o se sono stati predisposti degli opportuni filtri automatici per la stampante PostScript; in modo del tutto analogo possiamo stampare il file PostScript "tesi/cap1.ps", ad esempio con il comando "lpr tesi/cap1.ps", se la nostra stampante è una unità PostScript o se il sistema dispone di un opportuno filtro di conversione per il formato PostScript (ad esempio gs, anche noto come GhostScript). Se si dispone di un terminale grafico X Window un modo molto comodo per visualizzare e stampare un file PostScript è quello di utilizzare il programma ghostview, che fornisce una semplice interfaccia per GhostScript, guidata mediante l'uso dei menù.
Una volta inviato un certo file alla coda di stampa a tale job viene assegnato un identificativo numerico progressivo, il job id; per vedere l'elenco dei job presenti nella coda in attesa di essere stampati, si deve utilizzare il comando lpq (line printer queue). Per interrompere la stampa di un determinato job ed eliminarlo dalla coda di stampa si deve utilizzare il comando lprm seguito dal job id. Naturalmente la coda di stampa gestisce job provenienti da utenti diversi: ogni utente può eliminare dalla coda solo i propri job, mentre soltanto root può rimuovere dalla coda di stampa lavori inviati da qualunque altro utente.
Anche se il nostro sistema non è collegato alla rete Internet o ad una rete locale, in genere dispone del servizio di posta elettronica (e-mail) per consentire agli utenti di comunicare fra di loro. Vengono anche resi disponibili alcuni strumenti di comunicazione diretta (chat) fra utenti.
Per usare questi strumenti bisogna essere in grado di reperire alcune utili informazioni sugli utenti del sistema; ad esempio, potremmo cominciare da... noi stessi! Il comando whoami ci comunica il nostro username; visto che è impossibile accedere al sistema senza conoscere il proprio username, il comando risulterà più utile quando, trovando un terminale libero, con un utente attivo, ma non presente fisicamente al suo posto di lavoro, vogliamo informarci su chi sia lo sprovveduto che ha dimenticato di effettuare il logout prima di andarsene, o anche, richiamato da uno script o da un programma batch, risulta utile conoscere l'identità dell'utente che sta eseguendo il programma stesso. Il comando tty visualizza il nome del terminale (fisico o virtuale) mediante cui siamo connessi al sistema.
Il comando who visualizza l'elenco degli utenti collegati in questo momento sul sistema:
$ who
root tty1 Apr 25 12:11
marina tty5 Apr 25 19:15
marco ttyp0 Apr 25 18:05
marco ttyp1 Apr 25 18:32
$ _
L'esempio precedente indica che al sistema sono collegati tre utenti, due dei quali (root e marina) accedono al sistema da terminali alfanumerici (tty1 e tty5), mentre il terzo (marco) accede al sistema mediante un terminale grafico ed ha aperto due finestre diverse (ttyp0 e ttyp1). Il sistema ci comunica anche l'ora in cui è stato effettuato il login.
Un output simile al precedente, ma più dettagliato lo possiamo ottenere con il comando finger:
$ finger
Login Name Tty Idle Login Time Office Phone
marina Marina Mori 5 0:02 Apr 25 19:15 [Stanza 418] 2212
marco Marco Liverani p0 Apr 25 18:05 [Stanza 203] 2237
marco Marco Liverani p0 1:07 Apr 25 18:32 [Stanza 203] 2237
root Amministratore 1 0:12 Apr 25 12:11
$ _
In particolare ci viene comunicato anche il vero nome di ogni utente collegato, eventualmente il nome del suo ufficio ed il numero di telefono; viene anche visualizzato il tempo di inattività (idle) dell'utente, cioè da quanto tempo non sta più intergendo con il sistema mediante il mouse o la tastiera.
Lo stesso comando finger può essere utilizzato per reperire informazioni ancora più dettagliate su un particolare utente del sistema:
$ finger marina
Login: marina Name: Marina Mori
Directory: /home/marina Shell: /bin/bash
Last login Tue Apr 25 19:15 ( ) on tty5
No Mail.
No Plan.
$ _
In questo caso, oltre ad alcuni dati già visti, ci viene comunicato anche il nome della home directory dell'utente, la shell che utilizza e la data dell'ultimo accesso al sistema; il messaggio "No Mail." ci informa che l'utente non ha posta elettronica giacente non ancora letta; se invece ci fossero stati dei nuovi messaggi da leggere, il sistema ci avrebbe informato sulla data e l'ora in cui l'utente ha letto per l'ultima volta la posta. Il messaggio "No Plan." ci informa invece che l'utente non ha predisposto un file per comunicare agli altri delle informazioni sul proprio lavoro o su altri aspetti della propria attività. Se nella home directory di Marina si fosse trovato il file ".plan" (un normale file di testo), il contenuto di tale file sarebbe stato visualizzato al posto del messaggio "No Plan.".
Per avere un tracciato degli ultimi collegamenti effettuati sul sistema dagli utenti si può utilizzare il comando last che, richiamato senza alcun parametro, visualizza la lista (anche molto lunga) degli ultimi collegamenti registrati sul sistema; siccome l'elenco può appunto essere anche molto lungo, conviene richiamare last utilizzando more per impaginare l'output con il comando "last | more". Si può specificare anche l'opzione "-n" (n è un qualsiasi numero intero positivo) per visualizzare soltanto gli ultimi n collegamenti; si può pure indicare come parametro lo username di un utente per avere la lista dei suoi ultimi collegamenti. Ad esempio:
$ last -3
marina ttyp3 192.168.1.64 Sun Aug 28 19:07 still logged in
marco ttyp2 woodstock Sun Aug 28 11:02 still logged in
root console localhost Fri Aug 26 19:54 - 20:17 (00:23)
$ last marco
marco ttyp2 woodstock Sun Aug 28 11:02 still logged in
marco ttyp1 woodstock Fri Aug 26 19:50 - 20:26 (00:36)
marco console localhost Fri Aug 26 13:09 - 19:00 (05:50)
marco ttyp3 luna.mat.uniro Thu Aug 25 09:26 - 19:15 (09:48)
...
$ _
Ora che sappiamo come verificare se un certo utente è collegato o meno al nostro sistema, possiamo compiere il passo successivo: è possibile fare in modo di visualizzare un messaggio sul suo terminale. Il comando da usare è write seguito dallo username dell'utente a cui si vuole scrivere ed, eventualmente, anche dal terminale su cui si vuole visualizzare il messaggio; una volta dato il comando si può scrivere il messaggio, anche su più righe; per terminarlo si deve battere Ctrl-d . Immediatamente sul terminale dell'utente specificato verrà visualizzato il messaggio, con tanto di indicazione del mittente.
Con il comando wall (write all) è possibile inviare un messaggio sul terminale di tutti gli utenti collegati al sistema; questo comando (che può risultare un po' fastidioso per chi riceve il messaggio), viene utilizzato da root per segnalare l'imminente spegnimento del sistema. Anche in questo caso dopo aver dato il comando si può immettere il messaggio da inviare agli utenti, terminando la composizione con i tasti Ctrl-d .
Un modo un po' più sofisticato (ed utile) di comunicare con gli altri utenti del sistema è offerto dal comando talk, che permette di stabilire una comunicazione bidirezionale con il nostro interlocutore, una specie di telefonata via terminale. La sintassi del comando è come al solito assai semplice: "talk username [terminale]" (come per il write, specificare il nome del terminale su cui effettuare il collegamento, non è indispensabile). Se l'utente specificato è effettivamente collegato, il sistema visualizza sul suo terminale un messaggio del tipo:
Message from TalkDaemon...
talk: connection requested by marco.
talk: respond with: talk marco
Se il nostro interlocutore accetta di iniziare il "talk" dovrà rispondere con un "talk marco" e a quel punto la sessione di chat avrà inizio: lo schermo dei due terminali viene diviso a metà, nella parte superiore vengono riportate le parole scritte dal proprietario del terminale, mentre in basso sono riportate quelle scritte dal suo interlocutore; per terminare il talk si deve battere Ctrl-c .
Questi due tipi di comunicazione (write e talk) hanno il limite di essere "volatili" quanto una telefonata: terminata la comunicazione di essa non rimarrà traccia da nessuna parte. Richiedono inoltre la presenza contemporanea sul sistema di entrambi gli interlocutori. Viceversa la posta elettronica è uno strumento di maggiore utilità proprio perché non è necessario che il destinatario del messaggio sia collegato al sistema nel momento in cui avviene la spedizione: i messaggi rimarranno giacenti nella mailbox dell'utente e potranno essere comodamente letti quando l'utente stesso si collegherà al sistema; in un certo senso è una sorta di potente servizio di segreteria telefonica. Ma non solo: i messaggi di posta elettronica non svaniscono nel nulla dopo che li si è letti, è infatti possibile salvarli su un file o stamparli su carta per poterli rileggere o riutilizzare in seguito. Forse la caratteristica più importante è che i messaggi di e-mail possono essere inviati anche a utenti di altri computer, pure se questi non sono utenti di un sistema Unix: infatti il protocollo di trasmissione della posta elettronica utilizzato su Internet e in generale su quasi tutte le reti TCP/IP è un protocollo standard e aperto (SMTP -- Simple Mail Transfer Protocol) e dunque è stato possibile implementarlo su ogni sistema operativo.
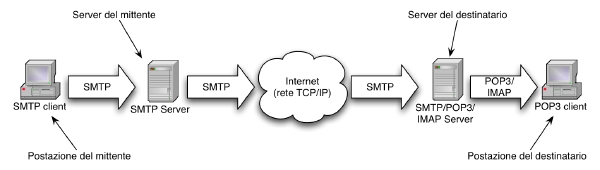
In modo estremamente schematico possiamo rappresentare come nel diagramma riportato nella figura seguente il processo di spedizione di un messaggio di posta elettronica. Un utente su una postazione client (un personal computer o anche una workstation Unix), utilizzando un programma di posta elettronica (Eudora, Apple Mail, Mozilla Thunderbird, Microsoft Outlook, ecc.) compone il proprio messaggio di posta indicando l'indirizzo del destinatario e lo invia. Il client di posta è configurato per comunicare con un determinato server SMTP che riceve il messaggio e gestisce la spedizione al destinatario; tipicamente, se il servizio è ben configurato, il server SMTP per la spedizione del messaggio ed il client di posta elettronica si trovano sulla stessa rete e comunque il server SMTP "conosce" il client o dispone di qualche meccanismo per stabilire che si tratta di una controparte nota e dunque teoricamente fidata. Una volta ricevuto il messaggio il server SMTP lo accoda provando ad inviarlo al server del destinatario ad intervalli di tempo regolari. Non è detto infatti che la consegna del messaggio riesca al primo colpo: ad esempio la rete potrebbe essere difettosa o il server di destinazione potrebbe essere temporaneamente spento o in manutenzione.
Quando finalmente il server di destinazione riceve il messaggio, se riconosce che si tratta di una mail destinata ad uno degli utenti di quel server, allora lo accoda nella mailbox del destinatario. Quando il destinatario utilizzando un mail client decide di verificare se c'è nuova posta in arrivo giacente nella propria mailbox, il suo client si collega attraverso il protocollo POP3 o IMAP al server di posta e, dopo essersi fatto riconoscere ed autorizzare, effettua finalmente il download dei nuovi messaggi.
Frequentemente sulla rete Internet vengono impiegate macchine Unix per realizzare i server di posta elettronica SMTP e POP3, spesso attraverso i programmi sendmail (SMTP server) e popper o pop3d (POP3 server), anche se sta prendendo largamente piede il sistema qmail. A meno di non voler utilizzare un client grafico evoluto (come Mozilla Thunderbird, ad esempio) in grado di connettersi ad un server SMTP/POP3 esterno e di sfruttare quindi i servizi offerti dal nostro Internet Service Provider, è necessario che la nostra macchina Unix implementi almeno il servizio SMTP per poter inviare messaggi all'esterno.(2) Tuttavia se ci limitiamo allo scambio di messaggi di posta elettronica tra gli utenti di una stessa macchina Unix, allora non è necessario disporre di un server SMTP, dal momento che sono gli stessi mail client che consentono di accodare i messaggi nella mailbox dei destinatario. Le mailbox degli utenti Unix sono infatti, tipicamente, dei semplici file di testo in cui i messaggi di posta elettronica sono riportati uno dopo l'altro. Le mailbox sono contenute in file identificati da un nome identico allo username dell'utente, memorizzati in /var/mail o /var/spool/mail (ad esempio il file "/var/mail/marco" contiene i messaggi dell'utente marco).
Il programma più elmentare per la gestione della posta elettronica è mail, presente su quasi ogni sistema Unix, ma se siete un utente alle prime armi forse sarà meglio utilizzare un programma più sofisticato e semplice da usare come elm (Electronic Mail for Unix) o pine (è il diretto concorrente di Elm: PINE=Program for Internet News & Email, ma anche Pine Is Not Elm). Descriviamo, in estrema sintesi, le principali operazioni da compiere per usare mail.
Per scrivere ed inviare un messaggio di posta elettronica ad un altro utente dovremo semplicemente digitare il comando mail seguito dallo username dell'utente; il sistema ci chiederà di inserire l'oggetto del messaggio, una sorta di titolo del messaggio stesso, quindi potremo iniziare a digitare il testo. Terminato il messaggio digiteremo all'inizio di una linea vuota un punto, che sta ad indicare la fine del messaggio stesso. Vediamo un esempio:
$ mail marina
Subject: cena in pizzeria
Cara Marina,
che ne dici di vederci per cena in pizzeria al Nuovo Mondo
questa sera alle 8?
Ciao,
Marco
.
EOT
$ _
Se Marina è collegata al sistema vedrà comparire sul proprio terminale il messaggio "You have new mail.", altrimenti questo messaggio sarà visualizzato al momento del login, al prossimo collegamento. Per leggere i messaggi giacenti nella mailbox Marina non dovrà fare altro che digitare a sua volta il comando mail:
$ mail
Mail version 8.1 6/6/93. Type ? for help.
"/var/mail/marina": 2 messages 1 new
1 andrea@woodstock Sun Aug 28 15:47 21/561 "gita al mare"
>N 2 marco@woodstock Mon Aug 29 23:21 18/547 "cena in pizzeria"
& 2
Message 2:
From marco@woodstock Mon Aug 29 23:21:42 2005
To: marina@woodstock
Subject: cena in pizzeria
Date: Mon, 29 Aug 2005 23:21:40 +0200 (CEST)
From: marco@woodstock (Marco Liverani)
Cara Marina,
che ne dici di vederci per cena in pizzeria al Nuovo Mondo
questa sera alle 8?
Ciao,
Marco
& q
Saved 2 messages in mbox
$ _
Se ci sono messaggi giacenti non ancora letti, digitando il comando mail si entra in un programma gestito mediante dei comandi formati da una sola lettera che devono essere digitati al prompt (che in questo caso è costituito dal carattere "&"). Nell'esempio Marina si limita a leggere il messaggio, digitandone il numero progressivo corrispondente, e poi ad uscire dal programma digitando q (quit). Uscendo dal programma i messaggi giacenti, letti ma non cancellati, vengono archiviati in una mailbox "locale" costituita da un file (tipicamente il file mbox) collocato nella home directory dell'utente, e possono essere recuperati per essere riletti successivamente, con il comando "mail -f" (o "mail -f mbox"). Per cancellare un messaggio si deve digitare d (delete) ed il numero del messaggio; per replicare ad un messaggio si deve digitare r (reply) ed il numero del messaggio. Battendo ? si ottiene una lista dei comandi principali del programma mail, mentre informazioni più dettagliate le fornisce la pagina di manuale ("man mail").
Esiste un altro modo, non interattivo, di spedire messaggi di posta elettronica mediante il programma mail e consiste nell'usare le numerose opzioni su linea di comando. La sintassi è la seguente:
mail -s "oggetto" destinatario -c altri indirizzi < file
dove oggetto è l'oggetto del messaggio, racchiuso tra virgolette, destinatario è lo username dell'utente a cui si intende spedire il messaggio, altri indirizzi è una lista di username di altri destinatari a cui inviare il messaggio "per conoscenza" (carbon copy); l'opzone "-c", con gli indirizzi che seguono, può anche essere omessa, visto che è una possibilità in più offerta dal programma, non indispensabile; alla fine della riga si digita il simbolo "<" (minore) seguito dal nome del file contenente il testo del messaggio. In questo modo è possibile preparare in precedenza il messaggio con il nostro editor preferito e poi, dopo averlo letto e corretto opportunamente, lo invieremo con questo comando.
Se desideriamo inserire alla fine di ogni nostro messaggio una firma piuttosto elaborata con cui personalizzare le nostre mail, è possibile prepararne il testo con un editor e salvarla nella nostra home directory con il nome ".signature". Il programma di posta elettronica la aggiungerà automaticamente alla fine di ogni messaggio in partenza.
Lavorare con il programma mail è comunque abbastanza laborioso e di certo poco intuitivo; molto più semplice e guidato, come abbiamo già accennato, è invece l'uso di elm o del suo diretto concorrente pine. Quest'ultimo in particolare è guidato completamente mediante dei menù molto chiari e dispone di un editor (pico) estremamente comodo da usare (nella figura seguente è rappresentato il menù principale di Pine); inoltre arricchire la mail con dei file allegati (attachment) è un'operazione che con pine è molto semplice.
PINE 4.63 MAIN MENU Folder: INBOX 2 Messages
? HELP - Get help using Pine
C COMPOSE MESSAGE - Compose and send a message
I MESSAGE INDEX - View messages in current folder
L FOLDER LIST - Select a folder to view
A ADDRESS BOOK - Update address book
S SETUP - Configure Pine Options
Q QUIT - Leave the Pine program
Copyright 1989-2005. PINE is a trademark of the University of Washington.
? Help P PrevCmd R RelNotes
O OTHER CMDS > [ListFldrs] N NextCmd K KBLock
In ambiente Unix si parla di processo per indicare un programma in esecuzione. Sappiamo che Unix è un sistema operativo multitasking, ma fino ad ora abbiamo sfruttato questa caratteristica solo grazie alla multiutenza, che ci permetteva di "toccare con mano" il fatto che la macchina, avendo più utenti collegati contemporaneamente, stava effettivamente elaborando più di un programma.
Per sfruttare pienamente e con comodità il multitasking si deve disporre di un terminale grafico che ci permetta di aprire sullo schermo più finestre in cui lanciare contemporaneamente diversi processi in modalità interattiva; è possibile fare altrettanto su un normale terminale alfanumerico, ma anche in questo caso si deve disporre di un programma (ad esempio screen) che ci consenta di simulare un ambiente con più finestre. Vedremo in maggiore dettaglio l'ambiente X Window in seguito, per ora ci limiteremo a dire che è possibile lanciare delle applicazioni che lavorano autonomamente ed indipendentemente dalle altre in una regione dello schermo (finestra) riservata ad ognuna di esse.
Per lanciare un'applicazione, come al solito è necessario dare un comando al prompt della shell, ma così facendo, come abbiamo visto fino ad ora, non possiamo utilizzare contemporaneamente sullo stesso terminale un altro programma, almeno fino a quando non saremo usciti dal programma in esecuzione. Esiste un modo per sganciare il processo "figlio" (il programma da eseguire) dal processo "padre" (ad esempio la shell da cui si lancia il programma) rendendo i due processi indipendenti ed autonomi. Se aggiungiamo il carattere "&" (e commerciale) alla fine della riga che invoca un certo comando, tale comando sarà eseguito in una "sessione" separata e quindi potremo utilizzare contemporaneamente la shell (da cui possiamo nel frattempo lanciare altri processi) ed il programma che abbiamo lanciato. Questo è possibile a patto che il programma "figlio" non richieda una interazione da parte dell'utente mediante il terminale (ad esempio un input da tastiera, o una visualizzazione molto "verbosa" di messaggi in output).
Vediamo un esempio molto semplice che possiamo provare anche su un normale terminale alfanumerico. Il comando yes visualizza una serie di "y" sullo schermo fino a quando non viene interrotto dall'utente. Per interrompere l'esecuzione di un programma dobbiamo battere Ctrl-c (break). Se invece di interromperlo volessimo solo sospenderne temporaneamente l'esecuzione, invece di break dovremmo battere Ctrl-z (stop):
$ yes
y
y
y
...
(l'utente batte Ctrl-z )
[1]+ Stopped yes
$ _
Il sistema ci informa che il programma identificato dal job number 1, che è stato lanciato con il comando yes, è stato momentaneamente interrotto. Il comando jobs ci permette di visualizzare la lista dei processi lanciati da quella shell; nel caso dell'esempio precedente avremmo il seguente output:
$ jobs
[1]+ Stopped yes
$ _
In questo momento abbiamo due processi attivi: la shell ed il programma yes che è momentaneamente interrotto. In particolare diremo che il processo attivo, la shell, è in foreground, mentre l'altro processo è in background; in uno stesso momento, nella sessione attiva su un determinato terminale, può esserci un solo programma in foreground, ma anche molti programmi in background. Per riportare in foreground il programma yes (e mandare quindi in background la shell) si deve usare il comando fg (foreground) seguito dal numero del processo:
$ fg 1
y
y
y
...
Avevamo citato precedentemente tra le unità disponibili su un sistema Unix, anche il device "nullo" /dev/null. Ora potrebbe tornarci utile. È possibile redirigere l'output di una applicazione verso una unità diversa dal device di output standard (il video del terminale) mediante l'uso del carattere ">" (maggiore). Proviamo a redirigere l'output del programma yes verso l'unità nulla, dando il comando "yes > /dev/null". Il programma è in esecuzione, ma sullo schermo non appare nulla, neanche il prompt della shell per poter lanciare altri programmi nel frattempo. Interrompiamo l'esecuzione di yes battendo Ctrl-c e proviamo a riavviarlo con il comando "yes > /dev/null &":
$ yes > /dev/null &
[1] 143
$ jobs
[1] 143 Running yes >/dev/null &
$ ps
PID TTY STAT TIME COMMAND
67 1 S 1:32 bash
143 1 R 0:02 yes
152 1 R 0:00 ps
$ _
Con l'aggiunta del simbolo "&" alla fine della linea di comando, abbiamo lanciato l'applicazione in background, mantenendo l'uso della shell per impostare altri comandi. Con il messaggio "[1] 143" il sistema ci comunica che l'applicazione yes è il primo processo lanciato da questa shell e, nella tabella di tutti i processi del sistema, gli è stato assegnato il numero 143 (questo non vuol dire che ci sono 143 processi attivi). Con il comando jobs verifichiamo gli stessi dati ed in più il sistema ci comunica che l'applicazione è attualmente in esecuzione (running). Il comando ps ci fornisce delle informazioni su tutti i nostri processi attivi, non solo quelli lanciati attraverso una certa shell; l'esempio mostra che nel nostro caso sono attivi tre processi, tutti sul terminale tty1: bash, la shell è attiva da un'ora e 32 minuti ed è momentaneamente sospesa ("S") perchè sta eseguendo il comando ps, che è stato appena attivato ed è in esecuzione ("R"), come pure il programma yes, attivo anche questo solo da qualche istante. Osserviamo infine che con il comando bg è possibile riavviare in background un processo precedentemente sospeso con Ctrl-z . Il comando bg accetta come argomento il job id preceduto dal simbolo di percentuale o il numero del processo.
Come abbiamo già accennato nelle pagine precedenti ogni programma attivo su un sistema Unix viene eseguito a nome e per conto di un determinato utente e da questo eredita i permessi per le operazioni sul filesystem; i processi di sistema vengono eseguiti, in genere, a nome dell'utente root: anche se questo non li ha lanciati digitando un comando sul terminale, durante la fase di bootstrap (la sequenza di start-up del sistema eseguita subito dopo l'accensione o un riavvio della macchina) vengono lanciati numerosi processi che rimarranno attivi (anche se in background) fino al successivo shutdown del sistema. Questi processi vengono chiamati in gergo "demoni" (daemons). Con il comando ps è possibile visualizzare anche l'elenco di tutti i processi attivi sul sistema; nelle opzioni del comando necessarie per compiere tale operazione, emerge una delle poche differenze tra Unix di tipo BSD e System V visibili anche all'utente generico. Sui sistemi BSD per visualizzare tutti i processi attivi bisogna aggiungere al comando ps le opzioni "-auxw", mentre sugli Unix SVR4 le opzioni sono "-ef"; l'output è molto simile in entrambi i casi; di seguito riportiamo un esempio estratto dall'output prodotto su una macchina Sun Solaris 8 (dunque una versione di Unix System V):
$ ps -ef
UID PID PPID C STIME TTY TIME CMD
root 0 0 0 Aug 16 ? 0:16 sched
root 1 0 0 Aug 16 ? 0:52 /etc/init -
root 2 0 0 Aug 16 ? 0:00 pageout
root 3 0 0 Aug 16 ? 67:57 fsflush
www 297 292 0 Aug 16 ? 0:38 /usr/apache/bin/httpd
root 112 1 0 Aug 16 ? 0:00 /usr/sbin/in.routed -q
root 284 1 0 Aug 16 ? 0:00 /usr/lib/nfs/mountd
root 255 1 0 Aug 16 ? 0:31 /usr/local/sbin/sshd
root 155 1 0 Aug 16 ? 1:01 /usr/sbin/inetd -s
root 172 1 0 Aug 16 ? 16:26 /usr/sbin/syslogd
www 299 292 0 Aug 16 ? 0:39 /usr/apache/bin/httpd
marco 10216 10214 0 21:50:29 pts/1 0:00 -tcsh
root 292 1 0 Aug 16 ? 0:04 /usr/apache/bin/httpd
...
L'output viene incolonnato e sulla prima riga sono riportate delle etichette che aiutano ad interpretare il significato delle righe successive: sulla prima colonna viene riportato lo username (UID) dell'utente che sta eseguendo il processo; nella seconda colonna viene visualizzato il process id (PID), ossia il numero progressivo che identifica univocamente un determinato processo; subito dopo, nella terza colonna, è riportato il numero identificativo del processo padre (PPID, parent process id), ossia del processo che ha eseguito il processo a cui si riferisce la riga in esame. Come si vede nell'esempio il programma sched è il primo ad essere lanciato (il PID è 0) e da quel processo sono stati lanciati altri tre processi: /etc/init (PID=1), pageout (PID=2) e fsflush (PID=3). A sua volta il programma init ha lanciato molti altri processi. È interessante notare che il padre del processo con ID=0 è il processo stesso (PID=PPID=0): deve pur esistere un processo da cui ha origine lo start-up del sistema operativo e dei processi principali, tuttavia, interpretando i codici PID e PPID di tale processo, sembra proprio che sia nato da se stesso; questo giustifica l'espressione gergale bootstrap che richiama l'idea che la macchina per partire (o per "salire", altra espressione nel gergo degli utenti Unix) sembrerebbe essersi sollevata da terra tirandosi per i lacci delle scarpe!
Nella colonna TTY viene indicato il terminale da cui è stato lanciato il processo; come si vede nell'esempio molti processi non sono associati a nessun terminale, visto che sono demoni lanciati automaticamente durante la fase di boot del sistema.
Con il comando kill è possibile interrompere forzatamente l'esecuzione di un processo (come la pressione dei tasti Ctrl-c per i processi in foreground). Insieme a kill si deve specificare come parametro il PID dell'applicazione che vogliamo terminare o il suo job number, preceduto però dal simbolo di percentuale "%". Ad esempio per interrompere il programma yes dell'esempio visto in precedenza i due comandi "kill 143" e "kill %1" sono equivalenti.
Il comando kill accetta alcune opzioni che consentono di modificare il segnale inviato al processo che si intende terminare: "-TERM" è l'opzione di default e invita il processo a terminare normalmente; l'opzione "-KILL" è invece più brutale e termina il processo immediatamente, anche se questo sembra non reagire a comandi di terminazione più "morbidi"; l'opzione "-HUP" infine consente, per quei processi che lo prevedono, di terminare e rilanciare il processo stesso.
Come abbiamo già accennato nelle pagine precedenti la shell Unix consente di definire delle variabili di sessione e di ambiente in cui è possibile memorizzare delle informazioni; tipicamente vengono usate per memorizzare durante la sessione di lavoro (le variabili vengono infatti cancellate automaticamente quando la sessione termina) alcune impostazioni e parametri di configurazione che consentono di rendere più confortevole la sessione di lavoro stessa. Le variabili di sessione valgono solo nell'ambito della shell in cui sono state definite; viceversa è possibile definire delle variabili di ambiente la cui visibilità è estesa anche a tutti i programmi che vengono lanciati dalla shell in cui la variabile è stata definita.
Per definire una variabile di sessione impostando il nome ed un valore per la variabile stessa si deve usare una sintassi differente a seconda della shell che si sta utilizzando. Sotto bash si deve semplicemente digitare "nome=valore" (ad esempio "pippo=pluto"); sotto tcsh invece si deve usare il comando set con la sintassi "set nome=valore" (ad esempio "set pippo=pluto").
Anche per la definizione di variabili di ambiente si devono usare comandi differenti a seconda della shell utilizzata: su bash il comando è export, mentre su tcsh il comando equivalente è setenv. Ad esempio si potrà digitare il comando "export pippo=pluto" oppure "setenv pippo pluto" per definire la variabile di ambiente pippo con il valore pluto.
In tutti i casi per eliminare una variabile si può usare il comando unset con la sola eccezione delle variabili di ambiente sotto tcsh che devono essere eliminate con il comando unsetenv.
Per visualizzare l'elenco delle variabili di ambiente definite con qualche valore si usa il comando set senza alcun parametro. Per visualizzare il valore di una variabile specifica si può invece usare il comando echo; per distinguere le stringhe di testo dai nomi delle variabili, questi ultimi devono essere preceduti dal carattere "$":
$ pippo=pluto
$ echo $pippo
pluto
$ echo pippo
pippo
$ unset pipppo
$ _
Una variabile di ambiente molto importante è la variabile PATH: quando diamo un comando, la shell va a cercare il file eseguibile con quel nome solo nelle directory del filesystem specificate nella variabile di ambiente PATH. Questa variabile viene usata ad esempio dal comando which che ci permette di scoprire in quale delle directory del path è collocato fisicamente il file eseguibile di un certo programma (ad esempio: "which ls"). La variabile PATH contiene una sequenza di directory separate tra loro dal carattere ":"; per aggiungere una certa directory (ad esempio /home/marco/bin) al path si può usare il seguente comando sotto Bash (o un comando equivalente sotto C Shell):
$ export PATH=$PATH:/home/marco/bin
$ echo $PATH
/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/home/marco/bin
$ _
Un'altra variabile di ambiente assai utile è quella che consente di definire il prompt della linea di comando. Anche in questo caso la sintassi dipende dalla shell che stiamo utilizzando: sotto bash la variabile da impostare si chiama PS1, mentre sotto tcsh si chiama prompt. Per definire la stringa da utilizzare come prompt si possono usare delle sequenze di caratteri che hanno un significato specifico. Ad esempio spesso si utilizza un prompt che indica lo username dell'utente, l'hostname della macchina su cui sta lavorando ed il path della directory corrente (ad esempio "marco@woodstock ~/src/perl$"); per ottenere questo prompt si deve dare il seguente comando su bash "export PS1=\u@\h \w\$", dove "\u" rappresenta il nome dell'utente, "\h" l'hostname della macchina e "\w" il path della directory corrente. Su tcsh invece il comando da utilizzare per ottenere lo stesso risultato è "setenv prompt "%n@%m %c3%#"".
Visto che la maggior parte dei comandi Unix ammette numerosissime opzioni, alcune delle quali sono effettivamente di uso molto comune, la shell consente di definire degli alias con cui rinominare i comandi complessi. Il comando alias consente di assegnare un nome ad un'istruzione anche molto estesa; ad esempio:
$ alias nproc='ps -auxw | wc -l'
$ alias ls='ls -F'
$ alias rm='rm -i'
$ _
Il comando alias senza alcun parametro visualizza l'elenco degli alias definiti nella sessione.
I comandi disponibili su un sistema Unix sono alcune centinaia: oltre ad essere impossibile riportarli tutti, sarebbe anche abbastanza inutile, visto che sono moltissimi i comandi che non ho mai usato e che probabilmente non userò mai. Ci limitiamo in questa sezione a descrivere per sommi capi alcuni comandi non indispensabili, ma che possono essere di una certa utilità. Per quanto riguarda gli altri, quelli che non hanno trovato spazio in queste pagine, il consiglio è il seguente: quando sentirete la necessità di un comando per svolgere un particolare compito, cercatelo, magari "sfogliando" le pagine di manuale, perché quasi sicuramente già esiste!
Abbiamo spesso usato, negli esempi della pagine precedenti, gli operatori di redirezione dell'input/output. Più in dettaglio possiamo dire che il simbolo ">" serve per inviare l'output standard (quello che normalmente finisce sul video del terminale) su un file o su un altro device; la sequenza ">>" consente di accodare l'output ad un file già esistente, senza cancellarne il contenuto. Per redirigere i messaggi di errore prodotti da un programma, che generalmente non sono inviati su standard output, ma su un canale denominato standard error, si deve usare l'operatore "2>". Il simbolo "<" serve invece per leggere l'input standard (quello che altrimenti sarebbe inserito manualmente dall'utente mediante la tastiera) da un file o da un altro device. Infine il simbolo "|" (pipe) serve a collegare il canale di output di un programma verso il canale di input di un altro programma: in questo modo ciò che verrebbe normalmente visualizzato in output eseguendo il primo programma, viene invece utilizzato come input per il secondo. Il seguente esempio utilizza tutti gli operatori di redirezione dell'I/O:
$ cat < lista | sort > lista.ordinata
$ _
Il programma cat (che, come abbiamo visto, serve a visualizzare il contenuto di un file) riceve l'input dal file lista; l'output di cat viene inviato mediante il pipe al programma sort (che serve ad ordinare i dati contenuti in una lista) che li invia in output al file lista.ordinata. Al termine dell'esecuzione di questo comando il file lista.ordinata conterrà gli stessi dati di lista, ma ordinati alfabeticamente.
Riguardo al programma sort è forse opportuno aggiungere che i comandi "sort < lista > lista.ordinata" e "sort lista -o lista.ordinata" avrebbero svolto efficacemente lo stesso compito del comando riportato nell'esempio precedente al solo scopo di illustrare l'uso di tutti i simboli di redirezione dell'I/O. Le opzioni "-r" e "-n" producono rispettivamente l'ordinamento inverso (reverse) e l'ordinamento ottenuto considerando le righe del file in input come numeri (per cui "10" è maggiore di "9", e non il contrario come avverrebbe con l'ordinamento alfabetico). Concatenando opportunamente il comando sort con du e head si può ottenere la "classifica" dei file che occupano più spazio in una certa directory, come nel seguente esempio che permette di visualizzare le tre mailbox più capienti tra quelle presenti nella directory /var/mail:
$ du -sk /var/mail/* | sort -rn | head -3
199904 /var/mail/root
54712 /var/mail/andrea
47600 /var/mail/marco
$ _
Esiste un altro modo per passare ad un comando o ad un programma l'output prodotto da un altro processo: il cosiddetto backtick. Consiste nel richiamare un determinato comando racchiudendolo tra "apici inversi" (il carattere con codice ASCII 96, da non confondere con l'apostrofo); in questo modo viene prodotta una stringa con l'output del comando, che può essere passata come parametro ad un altro programma. La differenza rispetto al pipe è sostanziale: con il backtick l'output di un processo non viene passato in input, come con il pipe, ma può essere utilizzato come parametro di un altro programma. Vediamo il seguente esempio in cui sono usati i comandi which e file che abbiamo già descritto nelle pagine precedenti:
$ which ls
/bin/ls
$ file `which ls`
/bin/ls: ELF 32-bit MSB executable SPARC Version 1, dynamically
linked, stripped
$ _
Uno strumento molto importante ed utile per operare sui file di testo è il comando grep: consente di cercare in un insieme di file una sequenza di caratteri (in gergo una stringa) rappresentata da un pattern descritto con una espressione regolare.
Un'espressione regolare è una sequenza di caratteri che esprime un pattern per identificare delle stringhe, utilizzando una sintassi estremamente potente in una forma sintetica e compatta. Ci limiteremo a descrivere solo poche regole per la composizione delle espressioni regolari, rimandando alla documentazione di sistema del comando grep per una illustrazione approfondita di questo potentissimo strumento. In una espressione regolare ogni carattere rappresenta se stesso, con poche eccezioni costituite da caratteri che assumono un significato speciale. Tra questi il punto "." indica un carattere qualsiasi, mentre i simboli "?", "+" e "*" sono dei quantificatori: rispettivamente indicano che il carattere o l'espressione che li precede deve comparire nella stringa zero o una volta, una o più volte, zero o più volte. Per indicare un carattere che nella sintassi delle espressioni regolari assume un significato speciale, basta farlo precedere dal carattere "\" (backslash); dunque la sequenza "\" in una espressione regolare rappresenta proprio il carattere backslash.
L'espressione regolare più generica è costituita dalla sequenza ".*", che rappresenta una stringa qualunque di qualsiasi lunghezza (compresa la stringa vuota); l'espressione regolare "ab.*b.a" rappresenta tutte le stringhe che iniziano con "ab", poi proseguono con una sequenza anche nulla di caratteri qualsiasi, quindi contengono il carattere "b", poi un carattere qualunque ed infine il carattere "a". Corrispondono a questa espressione regolare le stringhe "abbca", "abxyzwbza" e infinite altre; l'espressione regolare "a.*.txt" rappresenta tutte le stringhe che iniziano con la lettera "a", sono seguite almeno da un carattere e terminano con "txt".
Dunque con grep possiamo visualizzare tutte le righe di un file che contengono una sottostringa che corrisponde con il pattern rappresentato dall'espressione regolare riportata come parametro e delimitata da apici. L'opzione "-v" consente di invertire la selezione: tutte le righe del file che non contengono la stringa rappresentata dall'espressione regolare. L'opzione "-i" consente di effettuare una ricerca case insensitive, ossia considerando come uguali fra loro le lettere maiuscole e minuscole.
$ grep -i 'rossi' indirizzi.txt
Mario Rossi, via marmorata, Roma, 06 9182736
$ grep -v 'Roma' indirizzi.txt
Lorenzo Bianchi, via monte bianco, Milano, 02 7349014
Giuliano Verdi, v.le beethoven, Firenze, 055 8123492
Manuela Bianchi, via monte bianco, Milano, 02 7349014
$ _
Il comando grep è molto utile anche come filtro dell'output di un altro programma particolarmente "verboso"; il seguente comando, ad esempio, visualizza l'output del comando ps escludendo tutte le righe che contengono la stringa "root":
$ ps -ef | grep -v 'root'
UID PID PPID C STIME TTY TIME CMD
daemon 795 1 0.0 Aug 22 ?? 0:23.57 lpd Waiting
smtp 26927 1 0.0 Aug 31 ?? 0:00.07 /usr/lib/sendmail
andrea 172264 1 0.0 17:19:28 ?? 0:00.55 mwm -multiscreen
marco 198161 198152 0.0 22:43:40 pts/1 0:00.08 -tcsh (tcsh)
luca 184062 184244 0.0 19:30:41 pts/2 0:00.29 pine
luca 184244 184230 0.0 19:30:38 pts/2 0:00.07 -tcsh (tcsh)
$ ps -ef | grep -v 'root' | wc -l
7
$ _
Con il comando date il sistema ci fornisce la data e l'ora corrente; l'amministratore di sistema (root) con lo stesso comando può anche impostare la data e l'ora. Il comando cal senza alcun parametro ulteriore visualizza in forma sintetica il calendario del mese corrente; per avere il calendario completo di un intero anno basterà specificare l'anno desiderato di seguito al comando cal; così ad esempio "cal 1789" ci permette di scoprire che il 14 luglio 1789, giorno della presa della Bastiglia, era un martedì . Specificando due parametri il primo verrà interpretato come il numero progressivo di un mese ed il secondo come il numero dell'anno di cui si intende visualizzare il calendario; ad esempio:
$ cal 7 1789
July 1789
S M Tu W Th F S
1 2 3 4
5 6 7 8 9 10 11
12 13 14 15 16 17 18
19 20 21 22 23 24 25
26 27 28 29 30 31
$ _
Il programma calendar è un programma di utilità che consente di avere un promemoria delle attività da svolgere nei prossimi giorni. È basato sul contenuto di un file di testo denominato calendar che deve essere presente nella home directory dell'utente; il file deve contenere una attività (o un appuntamento) per ogni riga e le righe del file devono iniziare con una data nel formato "mm/gg" (ad esempio "6/7" per il 7 giugno). Ogni volta che il comando calendar viene invocato questo produce la stampa delle righe relative alla data odierna e al giorno successivo; il venerd\`i stampa gli appuntamenti del giorno stesso e dell'intero week-end. Vediamo un esempio:
$ date +%d/%m/%Y
01/09/2005
$ tail -6 calendar
08/30 Telefonare ad Aurora per prossimo incontro
08/30 Passare in biblioteca (chiude alle 13!)
09/01 Consegnare dispense del corso di crittografia
09/01 Riunione con Paola alle 11:00
09/02 Ricevimento studenti (9-13)
09/03 In pizzeria con Marina, Rita e Andrea
$ calendar
09/01 Consegnare dispense del corso di crittografia
09/01 Riunione con Paola alle 11:00
09/02 Ricevimento studenti (9-13)
$ calendar | mail liverani@mat.uniroma3.it
$ _
A volte si desidera tenere un file sul disco, magari senza utilizzarlo spesso; in tal caso, per risparmiare spazio, potrebbe essere opportuno comprimere tale file, ricodificandolo in modo opportuno. A questo scopo esistono i programmi di compressione che si occupano di generare un file in formato compresso che, pur contenendo le stesse informazioni, occupa meno spazio del file originale. Naturalmente quando vorremo accedere alle informazioni contenute nel file originale, dovremo eseguire l'operazione inversa, scompattando il file compresso, per ottenere nuovamente il file originale. Su Unix esistono implementazioni di numerosi programmi compattatori: gzip e compress sono sicuramente i più diffusi in questo ambiente. Con il comando "gzip file" si comprime il file eliminando il file originale ed ottenendo al suo posto un file con estensione ".gz"; per ottenere il file originale da quello compresso si deve usare il comando inverso "gunzip file.gz" (o anche "gzip -d nome.gz"). Sintassi del tutto analoga è quella del comando compress (e del suo inverso uncompress). I file compressi con gzip hanno estensione ".gz", mentre quelli trattati con compress hanno estensione ".Z".
Un po' diverso è il programma zip, che produce file compressi nello stesso formato utilizzato dai programmi PKZIP e WinZip, molto diffusi sui sistemi Windows. È possibile archiviare numerosi file all'interno di un unico file compresso. Ad esempio con il comando "zip sorgenti.zip src/*" si archiviano in formato compresso, nel file sorgenti.zip, tutti i file contenuti nella directory src. Per estrarre i file originali dal file "zippato" si deve usare il comando "unzip sorgenti.zip", mentre per vedere il contenuto del file compresso, senza però estrarre i file in esso contenuti, si può usare l'opzione "-v"; ad esempio "unzip -v src.zip".
Il comando tar (tape archive) è molto usato in ambiente Unix e di solito serve per archiviare (senza comprimere) in un file unico più file, magari sparsi in directory differenti. In particolare è molto usato per effettuare il backup dei file del sistema su un nastro. I file archiviati con tar hanno estensione ".tar", mentre quelli con estensione ".tgz" sono file in formato tar compressi con gzip. Per archiviare un insieme di file (e directory) in un file in formato "tar" si deve usare l'opzione "cfv": c=create, f=file (opera su file e non su nastro), v=verbose (visualizza sullo schermo del terminale i nomi dei file archiviati); ad esempio, per archiviare in "archivio.tar" tutto il contenuto della directory corrente si può usare il comando "tar cfv archivio.tar .". Per visualizzare il contenuto di un file archiviato con tar si devono usare le opzioni "tfv" (ad esempio "tar tfv archivio.tar"), mentre per estrarre i file si devono usare le opzioni "xfv" (ad esempio "tar xfv archivio.tar").
$ ls *.txt
lettera.txt nota_tecnica.txt pippo.txt
$ tar cfv archivio.tar *.txt
a lettera.txt 2K
a nota_tecnica.txt 5K
a pippo.txt 1K
$ tar tfv archivio.tar
tar: blocksize = 8
-rw------- 107/60001 2159 Feb 6 16:50 2005 lettera.txt
-rw-rw-r-- 107/60001 5079 Nov 30 17:53 2000 nota_tecnica.txt
-rw-r--r-- 107/60001 762 Nov 30 17:55 2000 pippo.txt
$ tar xfv archivio.tar pippo.txt
tar: blocksize = 8
x pippo.txt, 762 bytes, 1 tape blocks
$ _
Sulla linea di comando della shell è possibile attivare una potente calcolatrice con il comando bc. Si tratta di un ambiente di calcolo molto più potente di una semplice calcolatrice da tavolo, con cui è possibile definire anche variabili e funzioni, ma che, usato in modo più elementare, consente di eseguire facilmente dei calcoli. Per uscire dall'ambiente bc si può digitare il comando quit o battere i tasti Ctrl-d . L'opzione "-l" impone l'utilizzo della libreria matematica standard, per cui il risultato dei calcoli sarà visualizzato utilizzando anche la parte decimale di valori non interi; senza questa opzione i risultati delle operazioni vengono visualizzati troncando la parte decimale.
$ bc -l
bc 1.06
Copyright 1991-1994, 1997, 1998, 2000 Free Software Foundation, Inc.
This is free software with ABSOLUTELY NO WARRANTY.
For details type `warranty'.
(3+2)/2
2.50000000000000000000
quit
$ echo "(3+2)/2" | bc -l
2.50000000000000000000
$ _
Il programma bc può essere usato anche in modalità non interattiva, passando le espressioni da calcolare attraverso un file specificato come argomento sulla linea di comando o dal canale di input standard (standard input) tramite l'operatore di pipe, come nell'esempio precedente.
La fonte di informazione principale sui comandi Unix e sui programmi installati sul proprio sistema è costituita dalle cosiddette man pages, o pagine di manuale, che formano, in unione ad un comodo programma di consultazione, una vera e propria biblioteca di manuali on-line, sempre pronti ad essere consultati. L'insieme delle man pages è suddiviso per argomento in nove sezioni:
Ogni pagina di manuale è contenuta in un file diverso ed i file appartenenti ad una stessa sezione sono contenuti nella stessa directory; ad esempio i file con le descrizioni dei comandi della prima sezione possono trovarsi nella directory /usr/man/man1.
Se è presente nel sistema la pagina di manuale relativa ad un certo programma, potremo visualizzarla mediante il comando man seguito dal nome del programma. La visualizzazione mediante il comando man viene filtrata automaticamente attraverso more e quindi potremo scorrere facilmente il testo della pagina, anche se questa dovesse risultare molto lunga. Il comando apropos (equivalente a "man -k") consente di cercare fra le pagine del manuale quelle che riguardano il termine specificato come argomento.
Se invece di operare mediante un terminale alfanumerico stessimo lavorando su un X Terminal, potremmo usare, invece di man, il comando xman che ci permette di "sfogliare" le pagine del manuale mediante una interfaccia a menù utilizzabile con il mouse.
Ad esempio con "man man" si visualizzano le istruzioni per l'uso dello stesso manuale, mentre con "man mkdir" si visualizza la pagina di manuale relativa al comando mkdir:
$ man mkdir
MKDIR(1L) MKDIR(1L)
NAME
mkdir - make directories
SYNOPSIS
mkdir [-p] [-m mode] [--parents] [-mode=mode] [--help]
[--version] dir...
DESCRIPTION
This manual page documents the GNU version of mkdir.
mkdir creates a directory with each given name. By
default, the mode of created directory is 0777 minus
the bits set in the umask.
OPTIONS
-m, --mode mode
Set the mode of created directories to mode,
...
$ _
Le man pages hanno tutte un formato piuttosto simile: innanzi tutto viene descritta in modo sintetico la sintassi del comando (synopsis) quindi vengono elencate e descritte dettagliatamente le opzioni che è possibile specificare insieme al comando. Di solito alla fine della pagina è riportato l'elenco dei file di configurazione del programma stesso (files), l'elenco di altri comandi correlati (see also) ed eventuali problemi noti, riscontrati in situazioni particolari nell'uso del programma (bugs).

NOTE:
1. Riferendoci all'esempio riportato in precedenza, possiamo dire che /usr è la directory padre di /usr/bin e che quest'ultima è la directory "figlio" di /usr.
2. La corretta configurazione di questo servizio è un'operazione complessa e dunque esula dagli obiettivi di questa guida introduttiva; d'altra parte si tratta di una tipica attività di competenza del sistemista Unix che gestisce la nostra macchina, dunque come utenti del sistema possiamo contare sul fatto che tale servizio sia già stato predisposto da qualcun altro.
L'interfaccia grafica X Window
Alcuni strumenti per l'uso della rete Internet
Sintesi dei comandi principali
